Polish
From jmips
jMIPS symulator MIPS o otwartym zrodleTo jest jMIPS latwy w uzyciu open source MIPS symulator napisany w jezyku Java. Do tej pory powinienes juz sciagnac plik archiwum z kodem zrodlowym (aktualne kopie mozna znalezc na sourceforge jMIPS project pages w ktorym mozna znalezc ta dokumentacje w zawartosci podkatalogu doc/html. Zapoznanie sie z nia pomaga w nauce o architekturze MIPS oraz stwarza obeznanie z bardziej generalnymi koncepcjami systemow komputerowych i ich architekturami. Istnieje piec wersji kodu symulacji do przejrzenia i zabawy w archiwum, pokazanych tutaj od 1 do 5. Numery zwiekszaja sie wraz ze zwiekszajacym sie wyrafinowaniem kodu i modelu symulatora, a zatem:
Kolejne strony objasnia ci proces budowy i uzycia podstawowego symulatora w szczegolach a pozniej posuwajac sie dalej rozpatrza pozostale symulatory. Symulatory te nie roznia sie miedzy soba w tym jak sa zbudowane czy uzyte - tylko ich czesci wewnetrzne sa rozne co skutkuje w tym ze jeden jest szybszy od drugiego. Bedziesz chcial pracowac z kazdym symulatorem po kolei, byc moze z zamiarem jego poprawy aby sprawic by dzialal szybciej. To jak dlugo zabiera wykonanie calosci oraz poszczegolnych instrukcji jest jednym z glownych wyswietlanych danych wyjsciowych symulatora. Jesli chcesz uzyskac statystyki takie jak, jak dlugo poszczegolne klasy instrukcji zajmuja do wykonania w konkretnych warunkach bedziesz musial dodac kod samemu. To jest open source! Mozesz to zrobic. Kod jest wyraznie napisany i wyjasniony na tych stronach. Kompilacja i uruchomienie symulatora w JavaRozpakuj plik zip lub skompressowany plik tar(uzyskaj je ze strony jMIPS project page): % tar xzvf jMIPS-1.7.tgz lub % tar xzvf jMIPS-1.7.tgz
Ja wole produkowac rodzajowy kod bajtowy Java (JVM) za pomoca: % javac CPU/Cpu1.java w katalogu src, pozniej wynikly plik Cpu1.class moze zostac uruchomiony przez JVM na jakielkolwiek platformie. Mozesz to zrobic w Linuxie za pomoca: % java CPU/Cpu1 -q hello_mips Na przyklad: % java CPU/Cpu1 -q hello_mips32 Hello world % Aby zaimportowac zrodlo do Java NetBeans IDE, rozpocznij nowy projekt NB (nazwany 'jMIPS' przypuszczalnie) upewniajac sie ze wszystkie pola w oknie dialogowym glownej klasy 'Main Class' sa niezaznaczone. Jak tylko IDE zbuduje wszystkie katalogi i pliki kontrolne ktorych potrzebuje, skopiuj z katalogu src/CPU pliki *.java z archiwum kodu zrodlowego do nowego podkatalogu src/CPU projektu jMIPS ktory wlasnie zostal stworzony przez NetBeans. Uzyj systemowego polecenia do kopiowania. IDE wykryje zmiane i rozszerzy swoj widok drzewa 'Pakiety Zrodlowe' (jMIPS/src katalog) zeby zalaczyc pakiet CPU i jego pliki Java. Uwagi na temat uruchmienia modelu procesoraZnaczenie opcji dla lini polecen jest nastepujace:
% java CPU/Cpu1 hello_mips32 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) 3: 0.000000024s: 0x8003008c: addu $30, $29, $0 4: 0.000000030s: 0x80030090: sw $28, 16($29) ... 218: 0.000001567s: 0x8003000c: lui $3, -20480 219: 0.000001573s: 0x80030010: ori $3, $3, 16 220: 0.000001580s: 0x80030014: sb $3, 0($3) % Powyzsze uruchomienie wokonalo 220 instrukcji w czasie 0.000001580 symulowanych sekund (taktowanie zegara to 1 symulowany GHZ). To okolo 5 tykniec zegara na instrukcje wykonania.
% java CPU/Cpu1 -q hello_mips32 Hello world %
% java CPU/Cpu1 -d hello_mips32 text start at virtual addr 0x80030000 file offset 0x10000 text end at virtual addr 0x800300e0 file offset 0x100e0 text entry at virtual addr 0x80030080 file offset 0x10080 read 224B at offset 65536 from file 'hello_mips32' stack start at virtual addr 0xb0000000 stack end at virtual addr 0xb0100000 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29)widok drzewa ... %
Poprostu edytuj kod zrodlowy po to zeby dodac cokolwiek co lubisz, dodaj siebie do listy zaslug na gorze pliku kodu zrodlowego i przyslij swoj zmieniony kod - albo opublikuj go wlasnorecznie gdzies indziej, jak tylko sobie zyczysz.
Produkcja kodu maszynowego do uruchomienia w symulatorzejMIPS: symulator MIPS o otwartym zrodle Tutaj jest Hello world program juz zbudowany w kodzie maszynowym MIPS R3000. Kod zrodlowy (C) jest w pliku hello_mips32.c w archiwum misc/ a MIPS assembler to hello_mips32.s Kod maszynowy zostal skompilowany calkiem standardowo z zalaczonego zrodla: % gcc -static -o hello_mips32 -Wl,-e,f hello_mips32.c na platformie MIPS. Sprawdz instrukcje oblugi pod katem instrukcji gcc("man gcc") zeby dowiedziec sie dokladnie co opcje w tej linii polecen oznaczaja. Na platformie laboratoryjnej nie-MIPS ale Unix, nastepujace polecenia powinny osiagnac ten sam rezultat uzywajac mips-gcc cross-kompilatora (uruchom "setup MIPS" najpierw w swojej powloce systemowej po to zeby ustawic swoja sciezke wykonawcza pozwalajaca na wykrycie cross-kompilatora) % mips-gcc -DMIPS -mips1 -mabi=32 -c hello_mips32.c % mips-ld -Ttext 0x80003000 -e f -o hello_mips32 hello_mips32.o Symulator wygodnie zastepuje tutaj maszyne MIPS podczas wykonywania tego szczegolnego kodu MIPS. % java CPU/Cpu1 -q hello_mips32 Hello world % Bardziej skomplikowany kod maszynowy zawierajacy przerywania i peryferyjne urzadzenia moze pokonac symulator. Wejscie w kod zrodlowyOto kilka sugestii jak samemu "wejsc" w kod zrodlowy i miec do tego zabawe:
Jest on calkiem dobrze skomentowany taki jaki jest ale na pewno sa tam punkty gdzie wyda ci sie ze potrzeba wiecej(albo mniej, albo czegos innego) Edytuj go, dodaj siebie do listy zaslug i wyslij zmiany w projekcie. Jest to generalnie dobry sposob na poznanie kodu. Poskarz sie jak bardzo zle napisany i ciezki do zrozumienia on jest i napraw to. Znajdziesz obfita ilosc notatek w kolejnych sekcjach. Bedziesz chcial przejrzec kod z tymi notatkami w reku. Okaza sie one najbardziej pomocne jesli chodzi o zrozumienie cech o duzej skali pozostawiwszy tylko niuanse do wyjasnienia poprzez komentarze w kodzie zrodlowym.
Najpierw sprawdz w sieci co te instrukcje robia i jaki jest ich format w kodzie maszynowym. Ktos moze stwierdzic ze musi byc krzyzowka pomiedzy 'branch instruction' a instrukcja 'jump-and-link' juz od spojrzenia na sama nazwe. Zalozmy ze bgezal jest w wiekszosci taki sam bgez ale w wypadku pozytywnego tesu robi on to samo co instrukcja jal. Umiesc adres nastepnej instrukcji w adresie zwrotnym rejestru $ra. Jest to uzyteczne do implementacji warunkowego wywolania pod-rutyny. Sprawdz Google! Edytuj kod maszynowy "Hello world" za pomoca edytora binarnego ("bvi" bedzie dobrze ci dzialal na platformie Unix jesli jestes uzytkownikiem vi. Uzytkownicy emacs bede juz wiedziec ze emacs posiada edytor binarny) i zamien bnez v0, foo na kod maszynowy bgezal v0, foo. Przetestuj swoj zmodyfikowany emulator na zmodyfikowanym kodzie maszynowym. Bedziesz musial zrobic pewna zmiane wyrownajaca w programie po to zeby zachowac i przywrocic $ra rejestr adresu zwrotnego wokol galezi, ale zobaczysz ze sama galaz dziala ja nalezy.
Uwagi na temat kodu podstawowego modelu procesora MIPSRegularnosc zestawu instrukcji MIPS skutkuje bardzo przejrzystym kodem symulatora. Kod symulatora został również napisany w celu wytworzenia kodu, który jest jasny bez bycia jednoczesnie zbyt wyrafinowanym. W rezultacie, można sprawdzić, co robi każda instrukcja MIPS przez blizsze spojrzenie na odpowiedni obszar kodu. Klasa CPU1 jest niezbedna, posiada ona tylko minimum obiektowego opakowania w celu uczynienia jej łatwym do zapoznania. To jest automat skonczony! I tak jest w rzeczywistości. Cokolwiek potrzebujesz zobaczyć, aby zrozumieć model procesora CPU1 jest w kodzie w klasie CPU1 i nie musisz szukać nigdzie indziej. Zobaczysz ze jest tam tylko jedna duża pętla "while" w samym kodzie. Uzywa ona rodzajowego cyklu Von Neumanna pozyskaj-dekoduj-(odczytaj dane)-wykonaj-(zapisz dane) (popatrz na załączony rysunek po prawej stronie), tak jak jest to wdrożone we wszystkich głównych konstrukcjach procesorów od 1940 roku, a cała akcja jest osadzona wewnątrz tej jednej długiej pętli, z jednym krótkim odcinkiem poświęconym każdeu rodzajowi instrukcji MIPS. Więc znajdziesz tam około 10 lub 12 krótszych sąsiadujących odcinkow tworzących pętle. Na przykład, część majaca do czynienia z instrukcją "jump" wygląda tak ("pozyskaj" już zostało wykonane na początku pętli, po to aby wczytać następną instrukcję do rejestru IR). To głównie komentarz blokowy:
To tylko 6 linii prawdziwego kodu, nie licząc komentarzy. Podsumowując, model zakodowany przez klasę CPU1 urzeczywistnia abstrakcyjna konstrukcje procesora Von Neumanna bez niskopoziomowych szczegółów takich jak na przyklad elektrony są przemieszane i nie powinienes miec w ogole zadnego problemu spogladajac na kod zeby zrozumiec co on robi jako hardware(wskazówka: kiedy patrzysz na mała częśc kodu źródłowego, spojrz na nia z konkretnym pytaniem na uwadze, takim jak: jak funkcja X jest użyta, po to zebys mogl zrobic z niej wlasny uzytek i zignoruj wszystko inne; powtorz az wszystko jest zrobione). 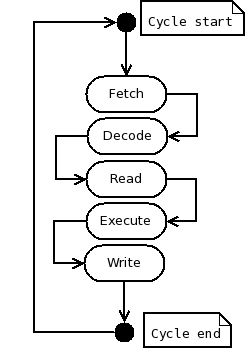 Różnica w stosunku do rzeczywistego sprzętu jest to, że kod może zrobić tylko jedną rzecz naraz, a rzeczywiste wyniki fizyka w sprzęcie robić wszystkie te rzeczy robione w kolejności tutaj wszyscy w tym samym czasie podczas cyklu procesora. Jednak wykonanie jest okreslane za pomocą metod klasy Clock a końcowy sprawozdanie dla ciebie tego, co sie wydarzylo ma miejsce tylko wtedy, gdy pełny cykl procesor jest zakonczony. Więc porzadek w ktorym rzeczy sa wykonywane oprogramowaniu pomiędzy tymi punktami nie ma szczególnego znaczenia. Tak długo jak porzadek ten ma logiczny sens, model dziala. Na przykład, kod skoku powyżej zapisuje rejestr RA danymi odczytanymi z instrukcji w rejestrze IR. W prawdziwym zespole komputerowym, te dwie rzeczy dzieją się równocześnie, jako rezultat transmisji potencjalnego pola elektrycznego w poprzek przewodzącego drutu. W powyższym kodzie odczyt mam miejsce przed zapisem, poniewaz implementacja Javy wymaga aby odbylo sie to w taki w ten sposób! Nie możemy napisać w Javie "czytaj A i jednocześnie zapisz wynik w B". Fizyka świata rzeczywistego sprawia, że jest to łatwe w rzeczywistości! Sprawozdanie składników uczestniczących jednakze, zarejestruje ten sam czas symulacji wystąpienia zarówno dla odczytu jak i zapisu, i to wszystko co zobaczysz na końcu.
Uklad KlasyIstnieja nastepuja klsy gornego poziomu w kodzie zrodlowym. Tylko pierwsze piec zawiera kod warty dyskusji, ktora nastepuje ponizej tabeli:
Jest to tak zwany projekt modelu domeny. Klasy w kodzie oprogramowania odpowiadają realnym składnikom sprzętu w procesorze MIPS. Metody odpowiadają rzeczywistym fizycznym operacjom, które komponenty sprzętowe mogą wykonac. Wirtualne operacje, takie jak te które mogą być tworzone przez kombinacje prostych operacji, nigdy nie sa zaimplementowane w oprogramowaniu bez względu na to jak "wygodnie" moglo by się to wydawać, ponieważ nie mają one fizycznej egzystencji.
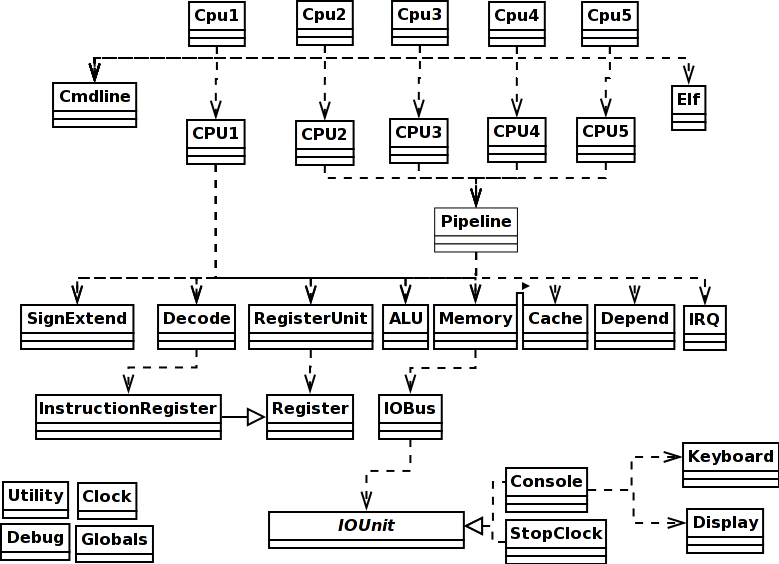
Diagram klas po prawej pokazuje zależności. Jeśli chcesz dodać jednoetapowe udogodnienie do symulatora CPU1, musisz wziąć pojedyncza duża petle pozyskaj-dekoduj-wykonywaj typu while w kodzie CPU1 i zatrzymać ja w oczekiwaniu na polecenie użytkownika przed każdym nowym cyklem. Powinienes sprawic ze polecenie s ("krok") od użytkownika wykona kolejny cykl; c ("kontynuj") powinno wysłać go z powrotem do krazenia w sposób ciągły; p ("drukuj") i numer rejestr lub adres pamięci powinien pokazać rejestr lub zawartosc pamięci, d ("wyswietl") powinieno być jak drukowanie, ale spowodować ze wydruk na ekranie nastąpi na każdym kroku. Głównym rutyna w CPU1Jest to szybkie streszczenie głównej rutyny w CPU1, klasy typu "wrapper", której zadaniem jest zrozumienie argumentow wiersza poleceń Javy ktore zostaly użyte, a następnie uruchomienie modelu procesora CPU1:
Mozesz tutaj zobaczyc, że metoda "main" analizuje wiersz poleceń uzywajac metody analizujacej w Cmdline, uzyskujac listę plików wykonywalnych, których to kod będzie uruchomiony. Pliki wykonywalne są w tzw formacie `ELF". ELF jest wieloplatformowym standardem używanym w wielu systemach operacyjnych bedacych dzisiaj w uzyciu i jest to format produkowany przez kompilatory gcc MIPS i assemblery. Główny podprogram posuwa sie dalej i ładuje te pliki ELF. Oznacza to, że wywoluje on konstruktor Elf na każdej nazwie pliku, który analizuje zawartość pliku i wydobywa informacje, takie jak punkty wejścia, zamierzone lokalizacje wirtualnych adresow itd., z których kazdy jest umieszczany w koncowym obiekcie Elf. Następnie metoda "main" buduje stos obszaru pamięci i procesora, powiadamia moduł pamięci CPU o tym stosie i jego zaplanowanym adres wirtualnym poprzez zawolanie do metody addRegion w jednostce pamięci. Nastepnie powiadamia moduł pamięci o różnych odcinkach kodu programu ktore uzyskala z plików wykonywalnych ELF poprzez więcej zawolan do metody addRegion. Pozostaje tylko ustawienie SP (`wskaźnik stosu") procesora CPU aby wskazywal na gore stosu, ustaw PC (`licznik programu") tak aby zarejestrowal adres zaplanowanego punktu wejścia programu - uzyskanego z pierwszego pliku wymienionego na lini poleceń - a następnie wywolaj nowo zbudowana i przygotowana metodę "run" procesora CPU. To na tyle. Więc oto wszystko co programista powinien wiedzieć o CPU1:
CPU1 model procesoraNastepujaca informacja jest wszystkim tym co programista widzi lub potrzebuje wiedzieć o klasie procesora CPU1. Jest tam (bardzo szkieletowy) konstruktor i jedna metoda
Metoda "run" nie jest trudna w koncepcji. Jest to poprosu jedna duza petla:
Tak jak jest to zaznaczone w komentarzach ta petla zawiera wnetrze cyklu pozyskaj/dekoduj/wykonaj. Oto ona:
Abstrakcyjna sekwencja pobierz/dekoduj/(odczytaj)/wykonaj/(zapisz) jest wyraźnie widoczna w kodzie. Jest tam jeden blok warunkowy poświęcony każdemu rodzajowi instrukcji (tj. jeden na kazdy odmienny opcode). Powyzszy fragment pokazuje blok zajmujacy sie operacjami ALU, które wszystkie mają wartość opcode 0. Różne rodzaje operacji ALU wyróżniają się różnymi wartościami pola "func" w instrukcji (ostatnie 6 bitów na końcu slowa o najmniejszym znaczeniu w ukladzie bigEndian). Wszystkie odmienne pola instrukcji w IR są poprzerywane, wlaczjac w to "func", w sekcji oznakowanej DEKODUJ!, A następnie funkcjonalność instrukcji jest zaimplementowana w krótkich odcinkach kodu Java oznaczonych PRZECZYTAJ!, WYKONAJ!, ZAPISZ! Co jest akceptowalnym a co nie jest akceptowalnym kodem w modelu procesoraZauwaz ze kod w "CPU1 run" swiadomie uzywa emulowanego zasobu komputerowego zeby wykonac cala prace Zamiast dodawac 4 do wartosci PC uzywajac na przyklad calej potegi jezyka Java ("pc+=4"). Instrukcja POZYSKAJ odczytuje PC uzywajac metody "czytaj" tegoz rejestru, dodaje 4 uzywajac wyznaczonej metody dodajacej fetch i kieruje rezultat z powrotem do PC uzywajac metody "zapisz" rejestru PC. To bardzo dlugi sposob, podczas gdy "pc+=4" mogloby zalatwic sprawe. Co sie tu dzieje ? Co jest dopuszczalne a co nie ? Jest to akceptowalne w modelu Java ze mozna "oznaczyc" wartosci danych wychodzacych jednostka sprzetu i uzyc ich jako dane wejsciowe. Zrobilismu to z "pc=..." i "...=pc". Cos takiego rowna sie uzyciu prostego okablowania do polaczenia sygnalow danych przez obwody CPU w obrebie pojedynczego cyklu zegara. Jest to w porzadku. Ale cokolwiek tak znaczacego jak "pc+=4" byloby oszustwem w Javie poniewaz zajmuje to czas i obwody w prawdziwym swiecie. Obiekty Java zastepujace komponenty sprzetowe CPU(alu, register_unit, itp) posiadaja wbudowany pomiar czasu i uzycie ich w kodzie Java powoduje ze symulowany zegar postepuje prawidlowo. Sa one dobre komputacjach. Komputacje zajmuja czas w realnym swiecie.Obiekty metod Javy posuwaja naprzod symulowany czas. Wszystko OK. Uzycie kodu Javy "pc+=4" magicznie osiagneloby wymagany efekt bez zabrania jakiegokolwiek czasu oraz symulowanego sprzetu. To nie jest emulacja prawdziwego swiata, to emulacja magii. Nie OK. Wiec jakakolwiek arytmetyka musi zostac wykonana uzywajac obiektow Javy reprezentujacych komponenty sprzetowe, nie arytmetyke Javy. Poniewaz sekcja DECODE jest tutaj napisana w kodzie typu "inline", co sprawia ze wrazenie ze nie zabiera ona w ogole zadnego symulowanego czasu, na koncu kodu osadzono aktualizacji zegara aby utrzymanie czasu bylo szczere. Przeciwnie, sekcja FETCH nie wymaga dodatkowych aktualizacji czasu, ponieważ zabrany czas jest zdominowany jest przez instrukcję odczytywana z bufora / pamięci, a zegar jest aktualizowany wlasciwie przez wywołanie jednostki dostepu pamięci w tej części kodu. Zasada pisania kodu symulatora takiego jak ten jest to ze można używać zmiennych kodu Java do przechowywania wartości, ale nie dalej niż (mniej niż), tym czym w koncepcji jest jeden symulowany interwał zegara. Są one jak chwilowe wartości sygnału. Każda wartość sygnału, który ma przetrwać jednen symulowany interwal zegara lub dluzej musi być przechowywana w rejestrach. Oto co jest robione w kodzie "CPU1 run". Hipotetyczne przejściowe wartości pc i ir są przesyłane do PC i IR na przechowanie na wiele interwalow zegara. Obiekt conf ktory grupuje dane wyjsciowe dekodowania wygląda tak jakby trwal w niezmienionym stanie, ale jak tylko IR zmienia następny cykl, conf zostanie takze zmieniony. Więc koncepcyjnie reprezentuje on zestaw przewodów podłączonych do IR przez jakis obwod dekodowania i zadne dodatkowego przechowywania nie wchodzi tutaj w rachube. Klasy komponentów CPUPozostała część tego rozdziału dokumentuje klasy Javy, które reprezentują komponenty wewnątrz CPU. Jest to dokument referencyjny! Przeczytaj sekcję wtedy kiedy potrzebujesz to zrobic, a nie przed.
Klasa komponent RegisterUnitTen komponent zawiera "mała i super szybka pamięc" wewnątrz CPU.
Jednostki Register składaja się ze zbioru r liczacego 32 (w zasadzie nieco więcej,po to aby włączyć rowniez PC i IR) rejestrów. Nie ma nic zaskakujacego w kodach metody czytaj i zapisz. Czytaj i / lub zapisz jest wszystkim tym co może zostac zrobione rejestrom sprzętowym albo przez nie. Liczba argumentów wskazuje, ile rejestrow jest odczytywanych i zapisywanych w tym samym czasie (az do dwóch odczytow i jeden zapis są obsługiwane jednocześnie). Typ "Bajt" dla indeksów rejestru jako argumentow jest po prostu po to zebys nie pomylil argumentow, które są w 5-bitowymi wskaźnikami rejestrów z argumentami, które są 32-bitowa zawartośćia rejestrów. Tak, moglibysmy użyć 'int' do reprezentowania obu, ale wtedy nie zauwazylbys, który jest ktorym patrzac na podpis typu metody, i nastapily by błędy programistyczne.
Jedyną rzeczą, warto odnotowania jest automatyczna aktualizacja zegara podczas użycia jednostki rejestru. To gwarantuje, że użycie tego komponentu prowadzi do uczciwego ewidencjonowania czasu w symulacji. Odczyt i zapis maja miejsce jednocześnie. Kiedy patrzymy na części kodu klasy Register, widzimy, że "zapisz" ma skutek w "nastepny cykl", więc można zrobić wiele różnych odczytow i jeden zapis aby zarejestrowac każdy z cyklow w oprogramowaniu, a będzie to wyglądać tak jakby to wszystko zdarzyło się na raz w symulatorze na końcu cyklu. Klasa ALUKomponent ALU zajmuje sie arytmetyka w obrebie CPU.
Klasa ALU jest znaczacym kawałkiem kodu, ale jest zupełnie prosta. Metoda wykonawcza składa się z dużej instrukcji switch, która wybiera krótki blok kodu do wykonania w zależności od wartosci func(kodu funkcji) dostarczonej jako argument. Kod łączy dwie liczby całkowite danych wejsciowych a i b w odpowiedni sposób w celu uzyskania rezultatu c i "jednego dalej" wskaznika z albo zera:
Powyżej zilustrowany jest tylko kod operacji dodawania, ale jest on idealna reprezentacja. Żaden z kodow ALU nie jest bardziej skomplikowany niz ten. Klasa elementu pamięciKomponent pamięci reprezentuje element pamieci o dostepie losowym (RAM) z punktu widzenia CPU. Ta implementacja tak naprawdę miesza dwa prawdziwe składniki sprzętowe, menedzera oraz jednostki pamięci. Grymaszeniem bylby podzial obydwu na dwa różne komponenty, poniewaz nie jestesmy zainteresowani modelowaniem pamięci w tym samym szczególe co modelowaniem CPU. Wolimy patrzeć w tej chwili na pamięć jak na lśniące, gładkie, czarne pudełko.
Obiekt pamięci wewnętrznie składa się z szeregu regionów. Istnieja one tak naprawdę jako "granice stref" skonfigurowanych po stronie menedżera pamięci naszej jednostki pamięci. Każdy region składa się z pierwszego adresu w pamięci, ostatniego adresu i sekwencji bajtów reprezentujących zawartość obszaru pamięci. W prawdziwym życiu, raz skonfigurowany (a konfiguracja zmienia sie blyskawicznie jak jeden proces za drugim jest ladowany do procesora), menedżer pamięci nakłada różne procedury na poszczególne regiony. Jeden region może być tylko do odczytu a inny może być do odczytu i zapisu. Jeden moze być buforowany a inny nie. Metoda addRegion służy do konfigurowania jednego regionu wiecej na jednostkę pamięci. Metoda Read32be pozniej po prostu przechodzi przez tablice regionów poszukując tej, która zawiera podany adres do wyszukania, a następnie zwraca dane zapisane w tym regionie zaczynajac od danego parametru "offset" kiedy znajdzie wlasciwy region. Metoda Write32be jest komplementarna:
Ktos moglby w końcu chciec zasygnalizować wyjątek kiedy brakujacy (tzn. nieskonfigurowany) region jest adresowany, ale na ta chwile ten kod wykonuje prostą rzecz i ignoruje problem. Jednostka pamięci zawiera także specjalne metody read8 i write8, które odczytuja i zapisuja tylko jeden bajt na raz. Choć mogą się wydawać tylko wygoda (i rzeczywiście, wewnętrznie one odczytuja i zapisuja 4 bajty na raz, podczas gdy mogą uzyc read32be i write32be), ich rzeczywiste przeznaczenie to wykonywanie mapowania pamięci We/Wy. Kiedy dostarczony adres jest prawidlowy, metody modułu pamięci read8 i write8 przekazuja próbę dostępu do "iobus" zamiast do pamięci. Za magistrala i dołączonych do niej leży kilka modułów We/Wy. Kod zostanie opisany bardziej szczegółowo poniżej, ale najbardziej istotne do zapamietania jest to że ten układ oznacza iz komunikacja ze specjalnym adresem pamięci pozwala aby znaki byly czytane z klawiatury i wyświetlane na ekranie. Nazywa sie to odwzorowaniem Wejścia/Wyjścia w pamięci. Sposoby w jaki "iobus" przechwytuje dane są wdrozone wewnątrz kodu jednostki pamięci w nastepujacy sposob:
"0" jest adresem We/Wy magistrali konsoli klawiatury, a "1" jest adresem We/Wy magistrali wyświetlacza konsoli. Za pośrednictwem tych przechwytywan, jednostka pamięci tlumaczy odczyty z adresu pamieci GETCHAR_ADDRESS na odczyty z magistrali We/Wy adresu 0, który to magistrala tlumaczy na odczyty z konsoli dołączonej do niej. Podobnie jest z PUTCHAR_ADDRESS i zapisami do konsoli. Kod jednostki pamięci read8 jest dokładniej reprezentowany nastepujaco, z pętlą przez liste portów zamiast zakodowanej komendy "if" pasujace adresy pokazane sa w tekście powyżej:
Porty składają się z adresu pamięci memAddr polaczonego z adresem magistrali busAddr - powinnien on być przetłumaczony przez jednostkę pamięci. Mogloby to ujsc nam plazem gbybysmy dodali pojedynczy port na jednym adresie pamięci do jednostki konsoli, ale ja wolałem zajac sie bardziej generalnym przypadkiem, w którym PUTCHAR_ADDRESS i GETCHAR_ADDRESS nie są konieczne identyczne, w taki oto sposob rejestrujac dwa różne adresy portów, które dają dostęp do dokładnie tej samej konsoli w ten sam sposób. Nie jest to znaczace marnotrastwo. Bardzo często zdarza sie w życiu ze jednostki We/Wy mają kilka alternatywnych adresów mapowan, z których wszystkie mogą być wykorzystane do dostępu. Nadmiar jest czasami przydatny i jest często obowiązkowy ze względu na zachowanie zgodności. Lista portów jest dołączona w obrebie jednostki pamięci w taki oto sposob: port.add(new Port(GETCHAR_ADDR, 0)); // tlumaczenie GETCHAR_ADDR -> magistrala 0 dodana port.add(new Port(PUTCHAR_ADDR, 1)); // tlumaczenie PUTCHAR_ADDR -> magistrala 1 dodana W późniejszej iteracji tego kodu, możesz zechciec aby pewne porty byly oznaczone jako READ_ONLY lub WRITE_ONLY! (tylko do odczytu lub tylko do zapisu). Na razie, każdy port ma obsługiwać zarówno odczyt i zapis. Chronometraż: podstawowy dostęp do pamięci jest ustawiony do wziecia pomiaru pikosekund MEMORY_LATENCY, domyślnie 2500, ie, 2.5ns. Możesz zmienić tę wartość poprzez manipulacje zmiennej statycznej MEMORY_LATENCY w globalnej klasie . Możesz też użyć "-o MEMORY_LATENCY = ..." w linii poleceń. Dostęp do urządzeń We/Wy poprzez We/Wy magistrali adresu mapowań trwa krócej, nominalnie CACHE_LATENCY, która jest domyślnie ustawiona na 1000 pikosekund, tj. 1 ns. Chodzi o to, że podczas zapisu, wszystko co się dzieje to to że dane odpalone sa na magistrale We/Wy a nastepnie procesor kontynuuje swoj cykl. Magistrala We/Wy działa niezalaznie zeby wysyłac dane do drukarki (na przykład), a drukarka działa niezaleznie zeby zbuforowac dane, a później je wydrukować. Podczas odczytu wszystko co się dzieje to to że urzadzenie buforu klawiaturu (na przykład) jest odczytywane poprzez magistralę pod katem znaków wpisanych wcześniej. Tusz nie jest rozpylany na papier, ani "keypress" wykonywany w obrebie okresu 1 ns. Ale w jaki sposób CPU radzi sobie z opóźnieniami wielkości dostepu pamięci? Są one dluzsze niz nominalna 1 ns związana z domyslnym taktowaniem zagara 1GHz i przynajmniej przy odczycie, dostęp do pamięci musi odbyc się w pełni w ramach cyklu zegara CPU. Odpowiedzia jest to że procesor wykonuje pojedynczy wyjątkowo wydłużony cykl dla odczytu i zapisu pamięći głównej. Ten wydłużony cykl ma określony czas trwania, ale jest on na tyle dlugi, że pamięć jest w stanie odpowiedzieć w czasie jego trwania. Ma on dlugosc 2.5 ns, co odpowiada mniej więcej pamięci która może dostarczyć 400 MB/s. To mniej niż połowa szybkosci pamięci pierwszego poziomu (L1 cache) (ktora spotkasz w projekcie CPU4). Będziesz musiał poczekać, aż spotkasz kod CPU5 zeby móc poprawić ta konstrukcje. |




