Français
From jmips
Open-Source Simulateur MIPS en JavaIl s'agit d'un simulateur MIPS open-source facile à utiliser en Java. Vous devez déjà avoir téléchargé le logiciel; consultez le site web de jMIPS pour une copie récente et les dernières mises à jour. Vous receverez une copie de ce document avec le téléchargement dans le répertoire doc/html.
Apprendre à le connaître aide à l'apprentissage de l'architecture MIPS et également à se familiariser avec des notions plus générales des systèmes informatiques et des architectures. Le processeur MIPS est disponible dans l’archive en cinq modèles différents, définis ici de 1 à 5. Le niveau de sophistication du modèle augmente proportionnellement avec le chiffre correspondant, ainsi:
Les pages ci-dessous vous mèneront à travers le processus de construction et d'utilisation du simulateur du processeur de base en détails, puis passera en considération les autres modèles. Les modèles ne diffèrent pas dans la façon dont ils sont construits ou utilisés - c'est seulement les entrailles qui sont différents et le résultat est qu'un modèle devient plus rapide qu'un autre dans le même contexte. Vous voulez apprendre à travailler avec chaque modèle, à son tour, peut-être avec l'objectif à l'esprit d'améliorer le modèle pour le faire exécuter plus vite. Le temps d'exécution de chaque instruction est l'une des sorties par défaut imprimées à partir du simulateur. Si vous souhaitez obtenir des statistiques telles que la durée nécessaire à l'exécution de chaque classe d’instructions dans des circonstances particulières, vous aurez à ajouter dans le code par vous-même. C'est un code libre. Le code est écrit clairement et expliqué dans les pages suivantes. Comment compiler et exécuter le simulateur de base MIPSSi vous voulez ou devez compiler le code source Java pour accéder au code exécutable, suivez les étapes suivantes, selon les outils auxquels vous avez accès. Puisqu'il y a différents choix d'outils que les utilisateurs sont habitués d'utiliser sous différents systèmes d'exploitation, les sous-sections suivantes sont spécifiques à un système d'exploitation. Compiler avec Linux ou UnixSi vous êtes sur Mac et utilisez un HFS ou HFS+ système de fichiers, allez dans les propriétés du système et activez la sensibilité à la casse. Désarchivez le fichier zip ou décompressez le fichier tar (obtenez les sur le site web de jMIPS) avec % unzip jMIPS-1.7.zip ou % tar xzvf jMIPS-1.7.tgz respectivement. Cherchez ensuite le répertoire src dans la hiérarchie des fichiers nouvellement décompressés et changez votre répertoire courant (utilisez cd). Je préfère produire le code Java pour la machine virtuelle Java (JVM), avec % javac CPU/Cpu1.java dans le répertoire src et ensuite le fichier Cpu1.class peut être exécuté par un JVM sur n’importe quelle plateforme. Vous pouvez faire ainsi sous Linux avec % java CPU/Cpu1 -q hello_mips Par exemple % java CPU/Cpu1 -q hello_mips32 Hello world % Compiler avec WindowsPour importer la source dans un Java NetBeans IDE, créez un nouveau NB projet (appelé "jMIPS", probablement), faites en sorte que les cases à cocher pour "Main Class", et autres, sont toutes non cochées. Une fois que l’IDE a construit tous les répertoires et les fichiers de contrôle qu’il a besoin, copiez les fichiers *.java du répertoire src/CPU qui se trouvent dans l’archive du code source dans un nouveau sous-répertoire src/CPU dans le répertoire du projet jMIPS qui vient d’être créé par NetBeans. Utilisez la commande copie du système d'exploitation. Le IDE détectera ce changement et élargira sa vue arborescence ‘Source Packages’ (le directoire jMIPS/src) pour inclure le package CPU et ses fichiers Java. Si vous préférez, vous pouvez systématiquement renommer les fichiers Java class pour chaque processeur, passant de Cpu1.java, Cpu2.java (et ainsi de suite) à WinCpu1.java, WinCpu2.java, par exemple. Vous aurez à renommer la classe déclarée à l'intérieur de chaque fichier pour qu'ils correspondent. Notes sur l'exécution d'un processeurLa signification des options de ligne de commande est la suivante
% java CPU/Cpu1 hello_mips32 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) 3: 0.000000024s: 0x8003008c: addu $30, $29, $0 4: 0.000000030s: 0x80030090: sw $28, 16($29) ... 218: 0.000001567s: 0x8003000c: lui $3, -20480 219: 0.000001573s: 0x80030010: ori $3, $3, 16 220: 0.000001580s: 0x80030014: sb $3, 0($3) % Cette exécution a exécuté 220 instructions en 0.000001580 secondes de simulation (le taux de l’horloge est simulé sur 1GHz). C'était environ 5 tops d'horloge par l'exécution d'instruction.
% java CPU/Cpu1 -q hello_mips32 Hello world %
% java CPU/Cpu1 -d hello_mips32 text start at virtual addr 0x80030000 file offset 0x10000 text end at virtual addr 0x800300e0 file offset 0x100e0 text entry at virtual addr 0x80030080 file offset 0x10080 read 224B at offset 65536 from file 'hello_mips32' stack start at virtual addr 0xb0000000 stack end at virtual addr 0xb0100000 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) ... %
S'il vous plaît modifiez le code source afin d'ajouter tout ce que vous voulez, mais ajoutez-vous vous-même à la liste des crédits dans le fichier, et envoyez votre code changé au projet ou publiez le vous-même ailleurs, comme vous voulez. Produire le code machine MIPS pour le processeurLe programme “Hello world” produit sur le MIPS R3000 code machine est disponible dans l’archive avec le nom de fichier "hello_mips32" dans le sous-répertoire "misc/". Le code source (langage C) de ce dernier se trouve dans le fichier « hello_mips32.c » qui est dans le répertoire « misc/ » de l’archive et son assembleur est « hello_mips32.s ». Le code source a été compilé pour produire le code machine avec la commande: % gcc-static-o hello_mips32-Wl,-e, f hello_mips32.c sur une machine MIPS réelle. Consultez le manuel pour la commande « gcc » (c.a.d., « man gcc ») pour savoir exactement la signification des options passer dans cette ligne de commande. Pour les plateformes Unix sans MIPS, ceci devrait produire le même résultat en utilisant le compileur commun "mips-gcc" (vous devez pratiquement exécuter une commande "setup MIPS" dans votre environnement (ou session) shell pour établir le chemin de recherche de votre exécutable afin de déterminer les parties composantes du compilateur commun. % mips-gcc-DMIPS-mips1-mabi = 32-c hello_mips32.c % mips-ld-Ttext 0x80003000-ef-o hello_mips32 hello_mips32.o Le modèle du processeur MIPS remplace parfaitment tous les fonctions d'une vraie machine MIPS pendant l'exécution du code machine de "Bonjour tout le monde" (Hello world). % Java CPU/Cpu1-q hello_mips32 Hello world Cependant, des codes machines plus compliquées impliquant des interruptions et des périphériques peuvent vaincre ce modèle. Entrer dans le code sourceVoici quelques suggestions pour la façon d'entrer dans le code source, et de s'amuser en même temps.
Il est assez bien commenté comme il est, mais il y aura sûrement des points où vous sentez qu'il a besoin de plus (ou moins, ou différents) de lignes commentaires. Editez-le, ajoutez-vous aux crédits dans le premier bloc commentaire du fichier, et envoyez les modifications au projet. Il s'agit généralement d'une bonne façon d'obtenir une connaîssance profonde du code. Plaignez-vous des parties mal écrites et difficiles à comprendre et corrigez-les. Vous trouverez de nombreuses notes sur le code dans la section suivante.Vous aurez besoin de ces notes en regardant le code.Les notes se révèleront très utiles en termes de compréhension des caractéristiques à grande échelle, laissant les nuances à être expliquées par des commentaires dans le code source.
Vérifiez d'abord sur le web ce que les instructions font et quel est leur format! Seulement à partir du nom, on peut dire qu'elles seraient un croisement entre une instruction de branchement et une instruction de saut-et-lien. Supposons que bgezal est sensiblement la même chose que bgez, mais que dans le cas d'un test réussi, il fait la même chose qu'une instruction jal (mettez l'adresse de l'instruction suivante dans le registre d'adresse de retour, le registre ra). Cela est utile pour réaliser un appel de sousroutine conditionnelle. Vérifiez-le avec google! Modifiez le code machine pour Hello world avec un éditeur binaire ("BVI" va bien sur Unix si vous êtes un utilisateur de vi; les utilisateurs d'Emacs savent déjà que emacs dispose d'un mode éditeur binaire) et remplacez le code machine debnez v0, fooavec le code machine pour bgezal v0, foo. Testez votre émulateur modifié sur le code machine modifié. Vous aurez besoin toujours d'un changement extra dans le programme afin de sauvegarder et de restaurer l'adresse dans le registre ra, mais vous verrez la nouvelle instruction de branchement fonctionner. Notes sur le code source du modèle d'un processeur MIPS simpleLa régularité de l'ensemble des instructions MIPS rend très transparent le code Java de chaque modèle de processeur. Le code a également été écrit avec l'objectif d'être clair, sans être trop sophistiqué.  Conséquemment, vous pouvez vérifier ce que toute instruction MIPS fait en révisant les paragaphes correspondant dans le code source. Le code Java de la classe CPU1 est impératif avec juste le minimum d'emballage orienté-objet. C'est une machine des états! Et c'est le cas aussi, dans la réalité. Tout ce dont vous avez besoin pour comprendre le modèle de processeur CPU1, vous le trouverez rapidement dans le code de la classe CPU1, ne le cherchez nulle part ailleurs. Vous verrez qu'il y a juste un boucle while grande dans le code. Il utilise le cycle chercher-déchiffrer-(lecture des données)-exécuter-(écrire des données) générique de Von Neumann (voir la figure à droite), tel qu'il existe dans tous les designs de processeurs depuis les années 1940. Toutes les actions du modèle sont incorporés dans cet boucle longue, avec une partie contiguë courte dédiée à chaque sousclasse d'instruction MIPS. Ainsi, vous y trouverez les 10 ou 12 sections contiguës qui composent le corps du boucle. Par exemple, la partie traitant des instructions de saut ressemble à ceci (la partie «chercher» (fetch) a déjà été faite au début de la boucle, afin de lire l'instruction suivante dans le registre IR). C'est majoritairement composé d'un bloc de commentaires:
Celles sont seulementes 6 lignes du code en totalité, sans compter les lignes de commentaires. Pour résumer, le modèle du processeur codé dans la classe CPU1 incarne une conception abstraite du processseur Von Neumann sans les détails de très bas niveau et vous devriez avoir aucun problème de compréhension en lisant ce matériel de temps en temps (astuce: lorsque vous regardez une petite section d'un code source, le regarder avec une question en particulier pour résoudre. Par exemple, trouvez comment la fonction X est utilisée afin que vous puissiez l'utiliser vous-même, et ignorez tout le reste; répétez jusqu'à la fin). La différence avec un processeur réel est que ce code ne peut faire qu'une seule chose à la fois. Toutefois, l'exécution est programmée à l'aide des méthodes de la classe Clock (Horloge) et le compte final de ce que s'est passé ne se produit que lorsque le cycle du processeur a été completé. Donc, l'ordre dans le logiciel entre ces deux points temporales n'est pas particulièrement important. Tant que l'ordre est logique, le modèle fonctionne. Par exemple, le code des sautes ci-dessus écrit le registre RA avec des données lues à partir de l'instruction dans le registre IR. Dans le processeur réel, ces deux choses se produisent simultanément, étant le résultat physiquement inévitable d'un champ de potentiel électrique transmis à travers d'un fil conducteur. Dans le code ci-dessus, la lecture doit passer avant l'écriture, parce que la mise en œuvre en Java le nécessite! Nous ne pouvons pas écrire en Java "lire et écrire A à la suite dans B simultanément". Mais l'univers réel le fait aussi simple que ça en réalité! La comptabilité contenue dans les composants impliqués pour le code Java, cependant, va enregistrer le même instant simulé à la fois pour la lecture et l'écriture, et c'est tout ce que vous verrez à la fin du cycle. Organisation des classesLes classes suivantes de niveau supérieur se trouvent dans le code source Java. Seulement les cinq ou six premières contiennent un code méritant discussion, et la discussion suit le tableau ci-dessous:
Il s'agit d'un soit-disant 'modèle domaine'. Les classes dans le code source correspondent à des véritables composantes matérielles dans le processeur MIPS. Les méthodes correspondent aux véritables opérations physiques que les composants matérielles peuvent faire. Les opérations virtuelles, telles que celles qui peuvent être composées pour les combinaisons des opérations simples, ne sont jamais mises en œuvre dans le logiciel, peu importe si cela semble pratique, car ils n'ont aucune existence physique. 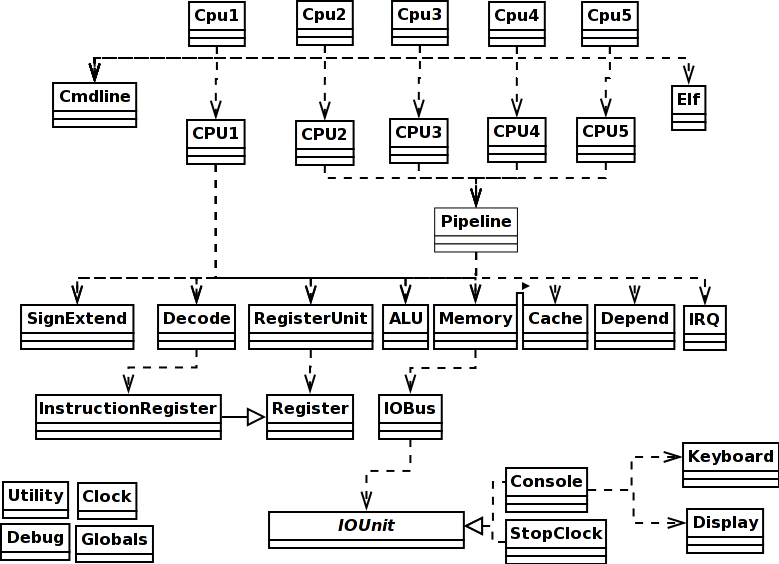
Le diagramme de classes à droite montre les dépendances. Si vous souhaitez ajouter une fonction qui permet l'exécution pas-à-pas du modèle CPU1, vous avez besoin de faire pauser le cycle chercher-decoder-exécuter au début de la boucle while, et y attendre l'entrée d'utilisateur avant chaque nouveau cycle. Vous devriez attendre un 's' ("step") de l'utilisateur pour indiquer qu'il faut exécuter encore un cycle, un 'c' ("continuer") devrait indiquer la rentrée à exécution continue, un p ("print") et un numéro de registre ou de l'adresse mémoire doit montrer le registre ou contenu de la mémoire sur l'écran; un d ("display") devrait être comme l'impression, mais provoquant l'impression aussi à chaque pas ensuite. La routine principale dans Cpu1Ceci est un précis rapide de la routine principale (main) dans Cpu1, la classe wrapper dont le travail consiste à interpreter les arguments de la ligne de commande Java::
Vous voyez ici que l'analyse principale de la ligne de commande utilise la méthode éponyme de la classe Cmdline. L'analyse implique l'obtention d'une liste de fichiers exécutables dans lequels se trouve t-il le code machine à exécuter. Les fichiers exécutables sont structurés selon le format connu sous le nom `ELF'. ELF est un standard multi-plateforme utilisé dans plusieurs systèmes d'exploitation actuellement en usage aujourd'hui et il est le format produit de les compilateurs gcc MIPS. La routine principale continue ensuite avec le chargement des fichiers ELF dans la mémoire dans le modèle du processeur CPU1. Autrement dit, le code Java fait appel au constructeur Elf pour chaque nom de fichier donné dans la ligne de commande. Le constructeur analyse le contenu du fichier et extrait quelques informations telles que les points d'entrée, les diferents zones d'adresses virtuelles, etc, tous placés dans l'objet Elf de Java que resulte. Puis le code construit la zone de la pile dans la mémoire du modèle, et indique à l'unité de mémoire son adresse avec un appel à la méthode addRegion. Il indique aussi à l'unité de mémoire les adresses des possiblement plusiers tronçons de code ramassés dans les fichiers exécutables ELF. Il reste à définir la valeur initiale du registre SP (pointeur de pile), mettre la valeur initiale du registre PC (compteur de programme) égale à l'adresse du point d'entrée du programme - obtenu à partir du premier fichier dans la ligne de commande - et ensuite appeler la méthode run du nouvellement construit et préparé processseur de la classe CPU1. Voilà c'est tout. Donc ce qui suit est tout ce que le programmeur a besoin de connaître de la classe Cpu1:
La section suivante vous montre ce que le mot run apliqué au modele processeur CPU1 veut dire. Le modèle du processeur CPU1Ce qui suit est tout le programmeur peut voir ou a besoin de connaître dans la classe CPU1 que represente en Java le foncionnement du processeur. Il y a un constructeur (defaute), et une méthode.
Le code Java de la méthode run n'est pas conceptuellement difficile. C'est juste la boucle ci dessous:
Comment dit dans le commentaire, la boucle contient le code qui fait ce que le cycle chercher-décoder-exécuter doit faire:
La séquence chercher/décoder/(lecture)/executer/(écrire) est clairement visible dans le code. Il y a un bloc conditionnel dédié à chaque sousclasse d'instruction (une par opcode distincte). Le fragment du code ci-dessus montre le bloc dédié au traitement des opérations ALU, ceux qu'ils ont tous l'opcode 0. Les différentes opérations ALU se distinguent par des valeurs différentes du champ final (function code) dans l'instruction (les 6 derniers bits à la fin du mot bigEndian). Tous les champs distincts de l'instruction sont éclatés, y compris le code de fonction, dans la section intitulée DECODER!, puis la fonctionnalité de l'instruction est mise en œuvre dans les sections courtes de code Java intitulées LIRE!, EXECUTER!, ECRIRE! Qu'est-ce que c'est l'acceptable et l'inacceptable dans le code d'un modèle du processeur?Notez que le code dans la classe CPU1 utilise consciencieusement les sous-composants pour son travail. Au lieu d'ajouter 4 à la valeur PC en utilisant la puissance du langage Java ("pc + = 4"), par exemple, le code FETCH lit le registre PC utilisant la méthode read de l'objet, puis il ajoute 4 utilisant la méthode execute de l'unite arithmetique feALU, puis il dirige le résultat vers le registre PC utilisant la méthode d'écriture de l'objet. C'est un détour longue où "pc + = 4" aurait pu faire le meme travail! Qu'est-ce que c'est que passe! Qu'est-ce qu'il y a qu'on permit ici et qu'est-ce que c'est qu'on ne permit pas? Il est acceptable dans le code Java à étiquetter les valeurs de sortie d'un unité de et les utiliser comme les entrées aux autres unités. Nous l'avons fait avec "pc = ..." et "... = pc". Ce genre de chose fait la meme chose que fait le câblage que connecte les signaux réelles au travers des circuits du processeur dans un seul cycle d'horloge. C'est bien acceptable. Faire quelque chose comme 'pc+=4' en Java serait un facon de tricher, car cela prend du temps et occupe des circuits dans l'univers réelle. Les objets Java que occupent le siege des composants matériels du processeur (ALU, unite des registres, etc) posedent une synchronisation intégrée avec l'horloge et les utiliser dans le code Java avance correctement l'horloge simulé. Tels objets doivrent etres utilise pour faire les calculs arithmetiques. Les calculs ont besoin d'un petit temps pour completer dans l'univers réelle, et les méthodes Java de tels objets avancent le temps simulé correctement. Tout OK. Pour contre, utilisant code Java comme "pc + = 4" obtient magiquement l'effet désiré sans faire passer du temps simulé et sans occuper les unites simulés! Cela ne veut pas imiter l'univers réelle, c'est l'émulation de la magie. Pas OK. Ainsi, toute l'arithmétique doit être fait en utilisant les objets Java représentant des composants matériels du processeur, et on n'est pas permit a utiliser les operations arithmétiques du langue Java. Car le code de la section DECODE est ecrivé explicitement en ligne ici, ce que signifie qu'il ne fait pas passer du temps simulé, une mise à jour d'horloge explicite a été incorporé à la fin de la section DECODE afin de maintener l'honnête du simulateur. Au contraire, la section FETCH n'a pas besoin de mettre à jour l'horloge avec un increment du temps supplémentaire parce que son temps d'execution est dominé pour l'effort a lire l'instruction du cache / la mémoire, et l'horloge est correctement mis à jour pour l'appel a la méthode d'accès a la mémoire dans cette section du code. La règle pour ecriver le code Java d'un modele simulé dans ce genre est qu'on peut utiliser des variables Java pour garder les valeurs interresants, mais pas pour plus qu'un seul cycle de l'horloge simulée. Ils sont comme des valeurs des signaux transitoires. Toute valeur du signal que dure plus qu'un cycle simulé de l'horloge doit être gardé dans un registre. C'est cette règle que a été observé en ecriver le code Java du modele CPU1. Les valeurs transitoires pc et ir sont acheminés vers les registres PC et IR ou ils sont gardés pendant multiples cycles d'horloge. Les classes du composants CPULe reste de cette section décrit les classes Java qui représentent des composants au sein de la CPU. Il s'agit d'un document de référence! Vous lisez une section juste quand vous en avez besoin et non pas avant. La classe de composant RegisterUnitCette composante constitue la 'mémoire petite et super rapide' à l'intérieur du processeur.
Les unités Register sont composées d'une collection r de 32 (en fait un peu plus afin d'incorporer PC et IR aussi) registres. Il n'y a rien de surprenant dans les codes du méthode read et write. Lire et / ou écrire est tout ce qui peut être fait à des registres matériels. Le nombre d'arguments indique le nombre de registres qui sont lues et écrites en même temps (jusqu'à deux lectures et une écriture sont supportés, simultanément). Le type 'byte' pour les indices du registre comme arguments est juste pour que vous ne confondez pas les arguments qui sont les indices de 5 bits de registres avec les arguments qui sont les 32 bits contenu des registres. Oui, nous pourrions utiliser 'int' pour représenter les deux, mais alors vous ne pourriez pas voir qui a été à la recherche de la signature du méthode, et les erreurs de programmation en suivra.
La seule chose à noter est la mise à jour automatique de l'horloge lors de l'utilisation de l'unité de registre. Cela garantit que l'utilisation de cette composante conduit à un honnête comptabilisation du temps dans la simulation. Lire et écrire se produisent simultanément. Quand on regarde le code du composant de la classe Register, nous allons voir que l'écrit prend effet lors du prochain cycle, de sorte qu'on peut faire de nombreuses distincte lectures et une écriture à un registre dans chaque cycle dans le logiciel, et ce sera comme si tout cela est arrivé à la fois dans le simulateur, à la fin du cycle. La classe ALULa composante ALU fait l'arithmétique dans le CPU.
La classe ALU contient une importante quantitè de code, mais il est entièrement simple. Le code de la méthode execute se compose d'une instruction switch qui choisit un bloc court de code à exécuter sur le func (code de fonction) la valeur fournie comme argument. Le code combine les deux integers a et b d'une manière appropriée pour produire le résultat c et un reste (carry) ou l'indicateur zéro z:
Le ci-dessus illustre uniquement le code de l'opération d'addition, mais il est parfaitement représentatif. Aucun code de l'ALU est plus compliqué que cela. Le composant du classe IOBusLe IOBus fait partie d'une communication à trois voies entre le CPU, la mémoire et lui-même. Lorsque le CPU adresse certaines locations du mémoire, l'accès est redirigé vers le gestionnaire de mémoire qui fait partie du unité de mémoire (memory unit) au lieu de la IOBus. Les méthodes read8 et write8 de la classe IOBus prennent une adresse de bus ( " 0 ", " 1 ", etc. ) au lieu d'une adresse mémoire. La redirection remplace une addresse bus (bus address) par une addresse memoire (memory address). Il y a une méthode addIO qui enregistre une unité d’I/O (par exemple un objet de Console) sur le bus, ce qui lui donne une adresse de bus. Les adresses des bus sont attribués dans l'ordre d'inscription pour chaque unité d'I/O qui en veut, à tour de rôle. Lorsque le CPU et l'unité de mémoire sont misent en place, le bus est construit et une console unique est enregistré au bus aux deux adresses de bus 0 et 1 comme ceci: IOBus iobus = new IOBus(); Console console = new Console(); short stdin = iobus.addIO(console); // console enregistré à l'addresse 0 du bus short stdout = iobus.addIO(console); // console enregistré à l'addresse 1 du bus Adresse 0 du bus sera la liaison utilisé pour GETCHAR_ADDRESS dans l'unité de mémoire, representant à une lecture depuis la console, et l'adresse 1 du bus sera la liason pour PUTCHAR_ADDRESS, representant à une écrit sur la console. L'interface complete aux méthodes du bus I/O est
IOUnit est une classe abstraite ( "interface" ). Les objets du Console correspondent à cette interface. Pour répondre aux exigences de cette interface un objet doit seulement avoir que les méthodes read8 et write8. Ces méthodes ne prennent pas dutout une adresse car elles sont associées qu'à leur propre unité d'I/O :
Un IOUnit produit un octet sur une requête de lecture, et absorbe un octet sur une demande d'écriture. Les objets de Console en particulier ont ces méthodes. L'unité de mémoire qui établit le code ajoute une console au iobus et relie son adresse bus à une adresse mémoire via la liste de port. Le résultat c'est que l'objet du console est accessible sur le iobus via mémoire mappée adressage (memory mapped addressing) de l'unité de mémoire. Pourquoi avons-nous pris la peine d’introduire un bus pour être un intermediare entre l'unité de mémoire et qu'est ce qu'il y a à ce moment d'une seule unité d'I/O, une console unique? C'est vraiment pour qu'on puisse modéliser les retards introduite par le fait que le bus ne peut être utilisé que pour accéder à un bloc d'I/O à la fois, et seulement un octet à la fois peut se déplacer sur le bus (dans une seule direction à la fois), et le fait que dans la vie réel le bus d'I/O est aussi relativement lent - 33 MHz, par rapport au CPU de 1 GHz. Le CPU peut exécuter 30 instructions dans le temps qu'il faut pour 1 octets de traverser le bus I/O. Si l'unité de mémoire tente d'accéder au bus alors qu'elle est déjà en cours d'utilisation, il y aura difficulté. Assurez-vous que les écritures au bus d'I/O sont au moins 30ns d'intervalles sinon vous ferez face à ces difficultés et des choses étranges commenceront à se produire tels que des écrits au bus se voient rejetés. Dans la pratique, ce n'est pas un grand problème. Quelle que soit le code machine que vous écrivez, c'est presque du jamais vu à produire une boucle suffisamment serrée pour faire deux écrit à l'I/O bus à moins de 30ns. La conception du CPU1 lutte pour delivrer 6 exécutions d'instructions machine durant ce moment. Ce n'est pas suffisant pour savegarder des registres, exécuter un saut à une sous-routine, faire quelque chose, revenir en arrière, restaurer les registres, augmenter un compteur de boucle, contrôler le saut du boucle, etc. Il y a du code qui produit du bruit sur le flot/flux d'erreur du simulation si le bus d'I/O arrive a submergé et cela n'arrive pas en pratique. Mias cela pourrait ce produire. Pour s'amuser, essayer de la produire, en écrivant le code machine approprié (via l'assembleur MIPS, bien sûr). Vous aurez un flux de plaintes sur l'écran. Des CPU réelles ont aussi leurs limites, et les véritables programmeurs leur écrivent. Vous pouvez écrire presque tout ce que vous voulez dans l'assembleur, et si le métal en dessous peut répondre comme vous en voulez ou pas est une différente question. Les véritables programmeurs suivent le principle de “ne le fait pas alors”. Par exemple, si vous consultez le code des véritables assembleur vous trouverez que chaque opération de saut (jump instruction) est suivie par un NOP parce que le pipeline et le mécanisme de chercher en avance les instruction font qu'il soit innevitable que l'instruction apres un jump sera exécuté .
|



{kind=link}