Bengali
From jmips
Authors: fse1975, fse4919 একটি MIPS প্রসেসর জাভা মধ্যেএই jMIPS সহজ-থেকে-ব্যবহার ওপেন সোর্স MIPS প্রসেসর জাভা মধ্যে. আপনি ইতিমধ্যে উচিত এই নথিপত্র মধ্যে আর্কাইভ (তারিখ পর্যন্ত কপি sourceforge jMIPS project pages মধ্যে থাকে) ডাউনলোড doc / html বিষয়বস্তু পাওয়া হবে subdirectory. 
খানে সফ্টওয়্যার জানতে চাওয়ার সাতিশয়, MIPS আর্কিটেকচারের বোঝা উন্নতি এবং কম্পিউটার সিস্টেমের আর্কিটেকচার এবং আরও সাধারণ ধারণার সঙ্গে ঘনিষ্ঠতা তৈরি. অনেকগুলি প্রসেসরের মডেল থেকে আর্কাইভের তাকান এবং সাথে খেলতে, মডেল 1, 2, 3 ইত্যাদি সংখ্যা মডেল বৃদ্ধি কুতর্ক মধ্যে আরোহন হিসেবে চিহ্নিত করা হয় এইভাবে:
নিচের পৃষ্ঠা ব্যবহার করে বিষদভাবে এবং সম্ভবত মৌলিক প্রসেসরের মডেল নির্মাণ প্রক্রিয়ার মাধ্যমে আপনি নেন, এবং তারপর হবে উপর থেকে অন্য মডেল বিবেচনা করা যেতে. এটি শুধুমাত্র আছে 'নাড়িভুঁড়ি' যে প্রতিটি মডেল ভিন্ন, এক মডেল একই প্রসঙ্গে মধ্যে হচ্ছে অন্য দ্রুততর মধ্যে যে ফলাফল - মডেল কিভাবে তারা বা নির্মিত ব্যবহৃত হয় না পৃথক. প্রতিটি পালা মডেল প্রসেসর মডেল তা আরও দ্রুত রান পেতে উন্নতি লক্ষ্য সাথে কাজ, চাইতে হবে. এটা কতক্ষণ পর্যন্ত সামগ্রিকভাবে এবং প্রতি নির্দেশ চালানো লাগে হল ডিফল্ট প্রিন্ট আউটপুট একটি. যদি আপনি এই ধরনের কতদিন নির্দেশাবলীর প্রতি বর্গ বিশেষ পরিস্থিতিতে চালানো লাগে হিসাবে পরিসংখ্যান প্রাপ্ত করতে চান, আপনি যে বিষয় নিজের জন্য কোড যোগ করতে হবে. এটা ওপেন সোর্স! আপনি তা করতে পারে. কোড পরিষ্কারভাবে হয় লিখিত এবং এখানে পাতাগুলোতে ব্যাখ্যা.
'কিভাবে মৌলিক MIPS প্রসেসরের মডেল চালানোর জন্য'হতে সরবরাহ zip সংরক্ষণাগার বা কম্প্রেস করা tar ফাইল মধ্যে রয়েছে একটি জাভা সংরক্ষণাগার ফাইল (একটি ঘড়া') (jMIPS প্রজেক্টের পৃষ্ঠায় ডাউনলোড লিংক থেকে তাদের একজন পাওয়া উচিত ). যদি না থাকে, তারপর যেতে পরের অধ্যায়. আপনি আর্কাইভ (উদাহরণস্বরূপ, আর্কাইভের নাম আপনার ডাউনলোড পছন্দের উপর নির্ভর করে) থেকে বয়াম ফাইল নিষ্কাশন করা উচিত: % unzip jMIPS-1.7.zip jMIPS-1.7/lib/CPU.jar বা % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/CPU.jar বা এছাড়াও misc ডিরেক্টিতে অবস্থিত বস্তুর সঙ্গে নিষ্কর্ষ % unzip jMIPS-1.7.zip jMIPS-1.7/misc/hello_mips32 বা % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/hello_mips32 তারপর Cpu1 বর্গ একটি জাভা ভার্চুয়াল মেশিন (JVM) হতে পারে, যে কোন প্ল্যাটফর্ম চালানো. আপনি লিনাক্স অধীনে এই সঙ্গে করতে পারেন: % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 উদাহরণস্বরূপ: % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 Hello world %
% jMIPS-1.7d/lib/CPU.jar % 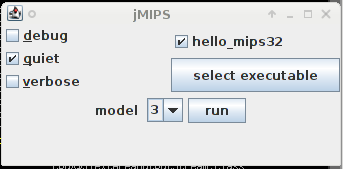 এবং আপনি উইন্ডোর ডান প্রদর্শিত হবে. এটা ইতিমধ্যেই করা হয়েছে misc / সোর্স আর্কাইভ এর, যাতে উপলব্ধ হিসাবে প্রদর্শিত হচ্ছে এবং ডিফল্ট অবস্থায় চালানোর জন্য প্রস্তুত থেকে তর্ক hello_mips32 এক্সিকিউটেবল ফাইল ব্যবহার করা হয়েছে; এবং "শান্ত" সুইচ ইতিমধ্যে খুব হয়েছে নির্বাচিত করা হয়েছে! CPU-র মডেল (চিত্র "3" করা) পরিবর্তন, "মডেল" নিয়ন্ত্রণ ব্যবহার. এরপর আঘাত "রান" এবং একটি উইন্ডো আপ রান থেকে আউটপুট ধারণকারী প্রস্থান করা হবে. (আপনি যদি সত্যিই আলোড়িত UML একটি ব্যবহারকারী এই
GUI সাথে আলাপচারিতার জন্য "কার্যকলাপ নকশা" দেখতে
চাই, ঠিক এই সামান্য আইকনের উপর ক্লিক করুন: 'কিভাবে মৌলিক MIPS প্রসেসরের মডেল কম্পাইল'আপনি যদি চান অথবা জাভা সোর্স কোড থেকে এক্সিকিউটেবল কোড কম্পাইল পেতে আছে, আপনি যা সরঞ্জাম আপনি উপলব্ধ উপর নির্ভর করে তাই করতে পারেন. যেহেতু সরঞ্জাম যে মানুষ বিভিন্ন অপারেটিং সিস্টেমে ব্যবহার বিভিন্ন সেট আছে, নিম্নলিখিত নির্দিষ্ট প্রতিটি অপারেটিং সিস্টেমের জন্য. 'লিনাক্স বা ইউনিক্স অধীনে কম্পাইল করার প্রণালী'যদি আপনি একটি ম্যাক হয়, এবং একটি HFS বা HFS + বিন্যাস ফাইল সিস্টেম ব্যবহার সিস্টেমের বৈশিষ্ট্য মধ্যে, এবং যান এই জন্য কেস সংবেদনশীলতা প্রবাহিত করান. আপনি এই প্রয়োজন হবে অন্যথায়, আপনি কেস ভাঁজ একটি অবস্থা টাল মধ্যে একে অপরকে, যা আপনি চান না সঙ্গে একাধিক ফাইল নাম আনয়ন পাবেন. জিপ বা কম্প্রেস করা tar ফাইল (jMIPS প্রজেক্ট পৃষ্ঠার থেকে তাদের পেতে ডাউনলোড লিংক) সঙ্গে সরান: % unzip jMIPS-1.7.zip বা % tar xzvf jMIPS-1.7.tgz যথাক্রমে তারপর সদ্য ফাইল অনুক্রমের মধ্যে src / নির্দেশিকা এবং তা আপনার বর্তমান ডিরেক্টরির ( CD jMIPS-1.7/src পরিবর্তন নির্দেশিকা কমান্ড সেটা করতে ব্যবহার) পরিবর্তন. আমি জেনেরিক জাভা বাইটকোড উত্পাদন পছন্দ জন্য একটি জাভা ভার্চুয়াল মেশিন (JVM), সঙ্গে % javac CPU/Cpu1.java মধ্যে src / ডিরেক্টরি, তারপর এবং যার ফলে Cpu1.class ফাইল একটি JVM দ্বারা করা যেতে পারে, যে কোন প্ল্যাটফর্ম চালানো. আপনি লিনাক্স অধীনে কাজের সঙ্গে পারে % java CPU/Cpu1 -q ../misc/hello_mips32 উদাহরণস্বরূপ: % java CPU/Cpu1 -q ../misc/hello_mips32 Hello world % একটি ঘড়া ফাইল নির্মাণের প্রণালী শুধুমাত্র প্রথম ভবনের একটি প্রশ্ন সমস্ত Java ব্যবহৃত ক্লাস ফাইল: % javac CPU/*.java % এবং তারপর একটি jar ঘড়া ফাইল সঙ্গে তৈরীর % jar cf ../lib/CPU.jar CPU/*.class % প্রকৃতপক্ষে, একটি jar ঘড়া শুধুমাত্র একটি প্যাকেজ কম্প্রেশন ছাড়া করা এর zip সংরক্ষণাগার, এবং একটি অতিরিক্ত উদ্ভিন্ন ফাইল সঙ্গে অন্তর্ভুক্ত. সুতরাং আপনি এটি মাত্র একটি জিপ আরকাইভার ব্যবহার করে এবং আপনি jar ঘড়া টুল অপরিহার্যভাবে প্রয়োজন হয় না করতে পারেন. বিস্তারিত অনুসন্ধান করুন: জাভা টিউটোরিয়াল সাইট অথবা একটি বিদ্যমান jar ঘড়া ফাইল তুলনা জন্য zip জিপ আরকাইভার ব্যবহার করে পরীক্ষা করুন. 'উইন্ডোজ অধীনে কম্পাইল করার প্রণালী'Alpha জাভা NetBeans IDE মধ্যে সোর্স ইম্পোর্ট, একটি নতুন NetBeans প্রকল্প (যাকে বলা হয় `jMIPS ', অথবা কিছু উপযুক্ত), এমনটা নিশ্চিত করা IDE এর সংলাপ` মুখ্য ক্লাসের জন্য-বক্স চেক' শুরু ইত্যাদি, সকল অবারিত. পরে IDE সব ডিরেক্টরি এবং নিয়ন্ত্রণ ফাইল দরকার নির্মিত হয়েছে, থেকে উৎস কোড আর্কাইভ নতুন src / CPU-র / ডিরেক্টরির' *. Java ব্যবহৃত ফাইল' কপি src / CPU-র / jMIPS প্রকল্প ডিরেক্টরি এইমাত্র NetBeans দ্বারা তৈরি করা হয়েছে subdirectory. সোজা ভিতরে সম্ভব যদি zip সংরক্ষণাগার থেকে একটি অপারেটিং সিস্টেম কপি কমান্ড ব্যবহার করুন. এই পথে অন্যথায় উইন্ডোজ ভাঁজ ফাইলের নামের কিছু হতে পারে ডিস্ক স্পর্শ ফাইল এড়ানো হল. যদি NetBeans ছিল একটি zip জিপ, অথবা zip জিপ, যে নির্ভুল হবে থেকে কম্পাইল থেকে ইম্পোর্ট মেনু পছন্দ. IDE আপনি সোর্স কোড এলাকা পূর্ণ এবং সনাক্ত করার জন্য একটি CPU-র "প্যাকেজ" এবং এর জাভা ফাইল অন্তর্ভুক্ত এর `উত্স প্যাকেজ 'ট্রি ভিউ ( jMIPS / src ডিরেক্টরি) একটি তালিকা প্রসারিত হবে. যদি উদাহরণস্বরূপ, আপনি প্রতিটি Cpu1.java, Cpu2.java, ইত্যাদি থেকে প্রসেসর WinCpu1.java, WinCpu2.java থেকে মডেল জন্য বরং ধারাক্রমে Java ব্যবহৃত বর্গ ফাইল নামান্তর হবে, ইত্যাদি বর্গ মধ্যে ঘোষিত নামান্তর আপনি হবে প্রতিটি ফাইলের সাথে সুসংগত হওয়া থেকে. জাভা NetBeans IDE মধ্যে সোর্স ইম্পোর্ট, একটি নতুন NetBeans প্রকল্প (শুরু গ 'একটি প্রসেসরের মডেল চলমান উপর নোট'কমান্ড লাইন অপশনের অর্থ হল নিম্নরূপঃ:
% java CPU.Cpu1 hello_mips32 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) 3: 0.000000024s: 0x8003008c: addu $30, $29, $0 4: 0.000000030s: 0x80030090: sw $28, 16($29) ... 218: 0.000001567s: 0x8003000c: lui $3, -20480 219: 0.000001573s: 0x80030010: ori $3, $3, 16 220: 0.000001580s: 0x80030014: sb $3, 0($3) % এই রান 0,000001580 কৃত্রিম সেকেন্ডে 220 নির্দেশাবলী (ঘড়ি হার 1 কৃত্রিম GHz) মৃত্যুদন্ড কার্যকর. প্রায় 5 নির্দেশ সঞ্চালনের প্রতি ঘড়ি থেকে.
% java CPU.Cpu1 -q hello_mips32 Hello world %
% java CPU.Cpu1 -d hello_mips32 text start at virtual addr 0x80030000 file offset 0x10000 text end at virtual addr 0x800300e0 file offset 0x100e0 text entry at virtual addr 0x80030080 file offset 0x10080 read 224B at offset 65536 from file 'hello_mips32' stack start at virtual addr 0xb0000000 stack end at virtual addr 0xb0100000 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) ... %
না ঠিক দয়া করে উত্স সম্পাদন দূরে যাতে অন্য কিছু চান, যোগ ফাইলের সোর্স কোড উপরের ক্রেডিট তালিকায় নিজেকে যোগ করুন, এবং আপনার পরিবর্তিত কোড পাঠাতে - অথবা এটা নিজেকে প্রকাশ অন্যত্র যদি আপনি চান. 'MIPS মেশিন কোড প্রসেসর চালানোর উত্পাদন'"সদস্য" প্রোগ্রাম, MIPS R3000 মেশিন কোড প্রস্তুত-নির্মিত hello_mips32 হিসাবে আর্কাইভের হল misc / মধ্যে ফাইল' . (সি ল্যাঙ্গুয়েজ) সোর্স কোড hello_mips32.c আর্কাইভের ফাইল misc / ডিরেক্টরির মধ্যে হয়, এবং এটি জন্য MIPS প্রতীকী ভাষান্তর হল hello_mips32.s. মেশিন কোড মান হিসাবে দেওয়া উৎস থেকে মেশিন কোড দিতে থেকে সংকলিত হয়েছে মাধ্যমে % gcc -static -o hello_mips32 -Wl,-e,f hello_mips32.c একটি বাস্তব MIPS মেশিনে, gcc কমান্ড (অর্থাৎ, "man gcc") খুঁজে বের করতে ঠিক কি কমান্ড লাইন দেওয়া অপশন মানে জন্য ম্যানুয়েল পৃষ্ঠা পরীক্ষা করুন. অ MIPS কিন্তু ইউনিক্স প্ল্যাটফর্মের উপর, নিম্নলিখিত একই ফলাফল mips-gcc ক্রস কম্পাইলার সংকলন (আপনি সাধারণত একটি "সেটআপ MIPS" আপনার শেল পরিবেশে কমান্ডের আদেশ সঞ্চালিত হতে পারে আপনার সেট ব্যবহার করে অর্জন করা উচিত এক্সিকিউটেবল অনুসন্ধানের পাথের মধ্যে ক্রস কম্পাইলার এর কম্পোনেন্ট অংশ নিতে): % mips-gcc -DMIPS -mips1 -mabi=32 -c hello_mips32.c % mips-ld -Ttext 0x80003000 -e f -o hello_mips32 hello_mips32.o একটি MIPS প্রসেসর এর সফ্টওয়্যার মডেল কার্যকররূপে জন্য একটি বাস্তব MIPS মেশিনের মধ্যে তেমনি যখন "হ্যালো বিশ্ব" মেশিন থেকে, কোড চালনাকারী. % java CPU/Cpu1 -q hello_mips32 Hello world তবে আরও জটিল মেশিন কোড ইন্টারাপ্ট এবং যন্ত্রানুষঙ্গ জড়িত এই মডেল সর্বনাশ হতে পারে. 'সোর্স কোড প্রাপ্ত'এখানে কিভাবে নিজেকে পেতে সোর্স কোড "মধ্যে" এবং মজা আছে প্রস্তাবগুলি:
এটি সম্পাদনা, উপরের নিজের ও ঋণ প্রকল্প থেকে সংশোধনী পাঠান. সাধারণত, একটি ভাল উপায় কোড নিজের অভ্যস্ত করান. থেকে সম্পর্কে অভিযোগ কিভাবে খারাপভাবে লেখা এবং / অথবা কঠিন এবং বুঝবার জন্যে এটা ঠিক করার চেষ্টা করা হয়, বিনা দ্বিধায়. আপনি নিম্নলিখিত বিভাগে কোড প্রচুর নোট পাবেন. আপনি কোড হাতে এই টীকার সঙ্গে হওয়া করতে পারেন. নোট বৃহদায়তন বৈশিষ্ট্য বুঝতে পরিপ্রেক্ষিতে সবচেয়ে বড়, প্রমাণ করা ছোড় শুধুমাত্র তারতম্য সোর্স কোড মন্তব্যের মাধ্যমে থেকে ব্যাখ্যা করা হবে.
ওয়েবের প্রথম থেকে কি নির্দেশ করতে দেখুন এবং কি তাদের জন্য মেশিন কোড বিন্যাস! আপনি যে কোনো শাখা শিক্ষাদান এবং একটি মাত্র নাম থেকে লাফ এবং লিংক নির্দেশ মধ্যে একটি ক্রস সেখানে অবশ্যই দেখতে হবে. মনে bgezal হল অনেক bgez কিন্তু একটি সফল পরীক্ষা অনুষ্ঠানের মধ্যে এটি একটি jal নির্দেশ হিসেবে একই কাজ করে (জায়গা না ফিরতি ঠিকানা নিম্নলিখিত নির্দেশ ঠিকানা নিবন্ধন হিসাবে একই , রা). যে একটি শর্তাধীন কল বাস্তবায়নের জন্য দরকারী. Google পরীক্ষা করে দেখুন!
আপনার পরিবর্তিত মেশিন কোড পরিবর্তন এমুলেটর পরীক্ষা করুন. আপনি প্রোগ্রাম একটি compensating পরিবর্তন করার জন্য এবং সংরক্ষণ $ রা ফিরতি ঠিকানা শাখা প্রায় নিবন্ধন পূর্বাবস্থায় ফিরিয়ে আনুন করা প্রয়োজন, কিন্তু আপনি নতুন শাখা নির্দেশ নিজেই কাজ দেখতে হবে. 'মৌলিক MIPS প্রসেসরের মডেল কোড নোট'MIPS নির্দেশ এর ধারাবাহিকতা একটি খুব স্বচ্ছ কোড স্থাপত্যশিল্প ফলাফল সেট. কোড হয়েছে বিদ্যুত্প্রবাহোত্পাদী কোড উদ্দেশ্য যা হচ্ছে অধিক বাস্তববুদ্ধিসম্পন্ন ছাড়া পরিষ্কার সঙ্গে লিখিত হয়েছে. 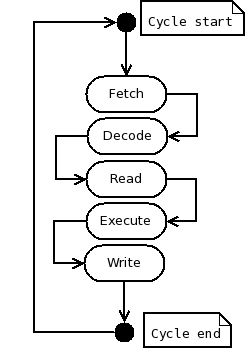 এর ফলে, আপনি 'চোখ বোলিং' কোড উপযুক্ত ক্ষেত্র দ্বারা আউট পরীক্ষা করতে পারবেন কি কোনো MIPS নির্দেশ করে. CPU1 বর্গ কোড শুধু বস্তু ভিত্তিক মোড়ানো ন্যূনতম করার জন্য সহজ মাধ্যমে পায়চারি করতে সঙ্গে অনুজ্ঞাসূচক. এটি একটি রাষ্ট্র মেশিন! এবং তাই এটা বাস্তবতা হল,. CPU1 বর্গ যে কোড যাই হোক আপনি দেখতে প্রয়োজন যাতে CPU1 প্রসেসরের মডেল বুঝতে হয়, এবং আপনি কোথাও হবে. আপনি মাত্র একটি বড় কোড সময় লুপ আছে দেখতে হবে. এটি সঞ্চালিত হয় জেনেরিক ভন Neumann-আনা পাঠোদ্ধার করা (ডাটা রিড) চালানো-(তথ্য লিখুন) চক্র (ডানদিকের সহচারী চিত্রে দেখুন), সব মূলধারার প্রসেসর ডিজাইন হিসেবে রূপায়িত 1940 সাল থেকে এবং সমস্ত কর্ম এই এক দীর্ঘ ভিতর এমবেডেড করা এক সংক্ষিপ্ত সংলগ্ন অংশ নিবেদিত MIPS নির্দেশ প্রতিটি ধরনের সঙ্গে লুপ,. সুতরাং আপনি প্রায় 10 বা 12 সংক্ষিপ্ত সংলগ্ন তৈরীর লুপ শরীরের আপ বিভাগে আছে পাবেন. উদাহরণস্বরূপ, অংশ জাম্প নির্দেশাবলীর সঙ্গে আচরণ দেখায় এই মত (ইতিমধ্যেই 'কারচুপি' লুপ শরীরের শুরু হয়েছে, করা হয়েছে যাতে এ IR রেজিস্টারে অন্তর্ভুক্ত পরবর্তী নির্দেশ পড়া). বেশির হল ব্লক মন্তব্য:
Alpha যে প্রকৃত কোড শুধু 6 লাইন, গণনা মন্তব্যটি লাইন না. এই সারসংক্ষেপের, মডেল CPU1 বর্গ দ্বারা এনকোড কম-স্তরীয় বিস্তারিত বর্ণনা ছাড়া একটি বিমূর্ত ভন Neumann প্রসেসর নকশা উদ্ভব অবিকল কিভাবে ইলেকট্রন প্রায় হচ্ছে খুঁজছেন কোড এবং বুঝতে কি তা না এবং আপনি সমস্ত কোন সমস্যা থাকা উচিত হার্ডওয়্যার (ডগা: যখন আপনি কোনো সোর্স কোড ছোট অধ্যায় তাকান এটা, একটি বিশেষ প্রশ্ন সঙ্গে তাকান, যেমন কিভাবে ফাংশন X তাই আপনি এটি ব্যবহার নিজেকে, এবং সবকিছু অন্য উপেক্ষা করতে পারেন ব্যবহৃত হয় যেমন; পুনরাবৃত্ত যতক্ষণ না করা). বাস্তব হার্ডওয়্যার সম্মান সঙ্গে পার্থক্য হল যে এই কোড শুধুমাত্র একটি সময়ে এক জিনিস, কি করতে পারেন যেহেতু প্রকৃত হার্ডওয়্যারে পদার্থবিদ্যা সমস্স এই কাজ একই সময়ে অনুক্রম এখানে সমস্ত একটি প্রসেসরের সাইকেল সময় জিনিসগুলি. যাইহোক, সঞ্চালনের হল সুবিধানুযায়ী ক্লক বর্গ পদ্ধতি এবং কি ঘটেছে হয়েছে চূড়ান্ত অ্যাকাউন্টিং শুধুমাত্র যখন একটি সম্পূর্ণ প্রসেসর চক্র সম্পূর্ণ করে. তাই আদেশ জিনিস সফ্টওয়্যার এই পয়েন্ট মধ্যে করা হয় কোন বিশেষ করে, না যে পর্যন্ত না ক্রম লজিক্যাল ইন্দ্রিয় তোলে - মডেল কাজ করে. উদাহরণস্বরূপ, লাফ উপরোক্ত কোড IR-রেজিস্টার নির্দেশাবলী থেকে ডাটা রিড সঙ্গে রা রেজিস্টার লিখেছেন. বাস্তব হার্ডওয়্যারে, এই দুটি জিনিষ একযোগে একটি বৈদ্যুতিক সম্ভাবনাময় ক্ষেত্র একটি পরিবাহী তারের জুড়ে প্রেরিত এর ফলে ঘটেছে. লেখার আগে পঠিত উপরোক্ত কোড ইন হবে, কারণ জাভা বাস্তবায়ন যে পদ্ধতিতে এটি করা আবশ্যক! আমরা জাভা লিখতে পারে না "A এবং B পড়া মধ্যে একযোগে ফলাফল লিখুন". বাস্তব মহাবিশ্বের পদার্থবিদ্যা বাস্তবে তোলে সহজ! জড়িত বস্তুগুলির দ্বারা অ্যাকাউন্টিং তবে, উভয় পাঠযোগ্য এবং লেখার জন্য একই ব্যাজ সময় সংঘটন এর মুহূর্ত এবং রেকর্ড হল, আপনি শেষ দেখতে হবে. Alpha 'শ্রেণী বিন্যাস'এইগুলি নিম্নলিখিত সোর্স কোড শীর্ষ স্তরের ক্লাস. শুধুমাত্র প্রথম পাঁচটি বা তাই নীচের টেবিলে আলোচনা, দর কোনো কোড অন্তর্ভুক্ত করা:
এটি একটি তথাকথিত ডোমেইন-মডেল নকশা. সফ্টওয়্যার কোড ক্লাস বাস্তব হার্ডওয়্যার MIPS প্রসেসরের মধ্যে শারীরিক উপাদান থেকে মিলা. প্রকৃত শারীরিক অপারেশন পদ্ধতি মিলা যে হার্ডওয়্যার উপাদান করতে পারেন. ভার্চুয়াল যেমন ঐ যে সহজ অপারেশন এর সমন্বয় করা সম্ভব মীমাংসিত হিসাবে অপারেশন হয় বাস্তবায়িত সফ্টওয়্যার কোন বিষয়টি কিভাবে "সুবিধাজনক" এটা কারণ তারা খুব শারীরিক অস্তিত্ব আছে মনে হতে পারে. না 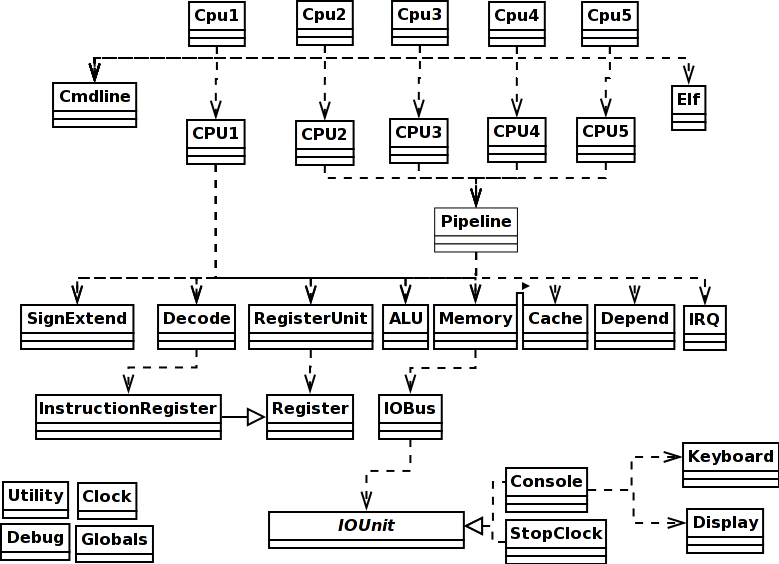
ডান উপর বর্গ ডায়াগ্রাম নির্ভরতা দেখায়. আপনি যদি Cpu1 simulator একটি একক পদক্ষেপ সুবিধা যোগ করতে চান আপনি একক বড়-আনা পাঠোদ্ধার-সঞ্চালনের সময় CPU1 কোড লুপ এবং প্রতিটি নতুন চক্র পূর্বে ব্যবহারকারীর ইনপুট জন্য বিরতি করা. গ্রহণ করা প্রয়োজন একটি c ("continue") এটি সাইকেলে অবিরত ফেরত পাঠাতে হবে; একটি পি ("প্রিন্ট" আপনি একটি s ("step") ব্যবহারকারী থেকে অন্য সাইকেল চালানো করা উচিত ) এবং একটি খাতা সংখ্যা বা মেমরি অ্যাড্রেস রেজিস্টার বা মেমরির বিষয়বস্তু প্রদর্শন করা উচিত; একটি d ("display") মুদ্রণ মত কিন্তু মুদ্রিত পৃষ্ঠা প্রতি ধাপে সময়ে সংঘটিত হতে হবে. 'Cpu1 প্রধান নিত্যকর্ম'এটি একটি "main" Cpu1 মধ্যে নিত্যকর্ম এর 'দ্রুত এবং ময়লা' সারমর্ম. রাপার ক্লাস যার কাজ এটি জাভা কমান্ড লাইন আর্গুমেন্ট আপনার ব্যবহৃত বুঝতে হয় এবং তারপর CPU1 প্রসেসরের মডেল সক্রিয় করা:
আপনি এখানে দেখতে পারেন যে "main" কমান্ড লাইন Cmdline ব্যবহার parses' পদ্ধতি বিশ্লেষণ এর একটি তালিকা প্রাপ্ত করার পদ্ধতি এক্সিকিউটেবল ফাইলের যার কোড পর্যন্ত চলবে. এক্সিকিউটেবল ফাইল কি `ELF বিন্যাস 'নামে পরিচিত হয়. ELF একটি ক্রস প্ল্যাটফর্ম মান অনেক ব্যবহার আজকের মধ্যে অপারেটিং সিস্টেমের ব্যবহৃত এবং বিন্যাস gcc MIPS কম্পাইলার এবং দ্বারা উত্পাদিত. "main" নিত্যকর্ম তারপর এগিয়ে যায় এবং এই ELF ফাইলগুলি লোড করা হয়. , যা কল পরী প্রতিটি ফাইলের নাম যা এন্ট্রি পয়েন্ট হিসাবে ফাইল এবং চায়ের তথ্য বিষয়বস্তু উদ্দেশ্যে ভার্চুয়াল ঠিকানা অবস্থানগুলি ইত্যাদি সব যার যার ফলে মধ্যে স্থাপন পেতে উপর রচয়িতা পরী বস্তু. তারপর' "main" মেমরি ও CPU স্ট্যাক অঞ্চলের তৈরী করে এবং স্মৃতি একক এর addRegion পদ্ধতিতে একটি মাধ্যমে কল স্ট্যাক এবং এর উদ্দেশ্য ভার্চুয়াল ঠিকানা সম্পর্কে CPU-র স্মরণ ইউনিট বলে. এটি প্রোগ্রাম কোড বিভিন্ন প্রসারিত এটা ELF এক্সিকিউটেবল ফাইল থেকে বাছাই করা হয়েছে addRegion আরও কলের মাধ্যমে আপ সম্পর্কে স্মৃতি একক চিহ্নিত করে. এটি CPU-র এর SP-' (`স্ট্যাক পয়েন্টার ') স্ট্যাক উপরের র দিকে নির্দেশ করে নিবন্ধন সেট অবশেষ. CPU-র সেট ' পিসি উদ্দেশ্যে প্রোগ্রাম এন্ট্রি পয়েন্ট অ্যাড্রেস (`প্রোগ্রাম কাউন্টার ') নিবন্ধিত প্রথম ফাইল কমান্ড লাইন উল্ল্যেখিত থেকে প্রাপ্ত তারপর ও সদ্য নির্মিত ও CPU' র রান প্রস্তুত পদ্ধতি কল. যে সব. সুতরাং নিম্নলিখিত সব প্রোগ্রামার Cpu1 সম্পর্কে জানা দরকার:
পরের অধ্যায় আপনি দেখায় কি উপায়ে 'এটি সঞ্চালিত হয়'. 'CPU1 প্রসেসরের মডেল'নিম্নলিখিত সব প্রোগ্রামার দেখতে পারেন অথবা CPU1 প্রসেসর বর্গ সম্পর্কে জানা দরকার. একটি (চমত্কার কঙ্কাল) রচয়িতা এবং একটি পদ্ধতি আছে.
' রান" পদ্ধতি কোড ধারণাগতভাবে কঠিন নয়. এটি শুধুমাত্র একটি বড় লুপ:
যেহেতু এটি মন্তব্যটি মধ্যে বলেছেন লুপ-আনা পাঠোদ্ধার-চালানো বৃত্ত অভ্যন্তর উপস্থিত রয়েছে. এটা এখানে আসে:
বিমূর্ত / কারচুপি / (রিড) পাঠোদ্ধার করা / / (লিখুন) অনুক্রম স্পষ্টতই কোড দৃশ্যমান চালানো হয়. একটি শর্তাধীন ব্লক নিবেদিত নির্দেশ প্রতিটি ধরনের (অর্থাৎ, স্বতন্ত্র opcode প্রতি এক) থেকে আছে. টুকরা উপরোক্ত ব্লক নিবেদিত ALU অপারেশন, যা সব opcode 0 আছে চিকিত্সা থেকে দেখায়. ALU অপারেশন ধরণের func নির্দেশ মধ্যে ক্ষেত্র (শেষ অন্তত bigendian বিন্যাস শব্দটি উল্লেখযোগ্য শেষে 6 বিটস) বিভিন্ন মান দ্বারা পৃথক হয়. সব IR-এ নির্দেশ স্বতন্ত্র ক্ষেত্র func সহ ভাঙ্গা আউট হয় অধ্যায় লেবেল ডিকোড মধ্যে! তারপর নির্দেশ এর কার্যকারিতা সংক্ষিপ্ত জাভা কোড লেবেল পড়ুন নামক অধ্যায়ে! রুপায়ন, চালানো! এবং লিখুন! 'কি গ্রহণযোগ্য এবং কি গ্রহণযোগ্য কোড একটি প্রসেসরের মডেল না'উল্লেখ্য conscientiously CPU1 রান কোড কোড CPU-র হার্ডওয়্যার হয় সব কাজ করে. পরিবর্তে পিসি মান জাভা প্রোগ্রামিং ভাষা শক্তি ("PC + = 4") ব্যবহার করে 4 যোগ করে, যেমন অধ্যায় আনা পিসি পিসি রেজিস্টার অবজেক্ট এর' পড়া পদ্ধতি ব্যবহার করে সার্চ, 4 যোগ ডেডিকেটেড ব্যবহার যোজক না আনা' পদ্ধতি, এবং রুট ফিরে পিসি পিসি রেজিস্টার অবজেক্ট এর' লিখুন পদ্ধতি ব্যবহার করে ফলাফল চালানো হয়. এই বিরক্তিকর প্রক্রিয়া যখন "PC + = 4" কাজ করা হয়তো! যাব কি আছে! কি এখানে কি করছে এবং কি না? এটি জাভা মডেল হল গ্রহণযোগ্য থেকে লেবেল হার্ডওয়্যার ইউনিট দ্বারা মান আউটপুট এবং ইনপুট অন্যান্য হার্ডওয়্যার একক হিসাবে তাদের ব্যবহার. আমরা 'PC = ...' সাথে যে করা এবং '... = PC '. জিনিস পরিমাণে এই সহজ তারের একটি ঘড়ি চক্র মধ্যে CPU-র সার্কিটের মাধ্যমে ডাটা সংকেত সংযোগ ব্যবহার করে সাজান. এটা ঠিক আছে. কিন্তু 'PC র উপর কিছু এমনকি একটি +4 হিসাবে দৃঢ়কায় ছেঁচড়ামি হবে জাভা কারণ এটা সময় এবং বাস্তব জীবনে তা সার্কিটের নেয় না. জাভা CPU-র হার্ডওয়্যার উপাদান (alu, register_unit, ইত্যাদি) জন্য স্থায়ী মধ্যে অবজেক্টের সময়জ্ঞান এমবেডেড তাদের এবং জাভা কোড তাদের ব্যবহার করে কৃত্রিম ঘড়ি অগ্রিম সঠিকভাবে তোলে আছে. তারা না কম্পিউটেশন জন্য ঠিক আছে. কম্পিউটেশন বাস্তব জীবনে করতে সময় লাগবে. জাভা বস্তু পদ্ধতি কৃত্রিম সময় আগাম. সব ঠিক আছে. "PC + = 4" কোনো কৃত্রিম সময় গ্রহণ ছাড়া প্রয়োজনীয় প্রভাব অর্জন করবে মত জাভা কোড ব্যবহার এবং এটা হয় কৃত্রিম হার্ডওয়েরের কোনো ব্যাপৃত করা না! যে বাস্তব জীবনে পরিস্থিতি না হয়, যে জাদু হয়. না ঠিক আছে. সুতরাং কোনো পাটীগণিত রয়েছে হবে জাভা CPU-র হার্ডওয়্যার উপাদান জাভা পাটীগণিত, না প্রতিনিধিত্ব অবজেক্টের ব্যবহার করে. কারণ ডিকোড অধ্যায় ইনলাইন জাভা কোড এখানে, যা এটি মত কোন সময় লাগে এ সব কৃত্রিম সময় করতে মনে মধ্যে সুস্পষ্টরূপে করা হয়, একটি স্পষ্ট ঘড়ি আপডেট ডিকোড কোড শেষে যাতে simulator রাখা হয়েছে এমবেড করা হয়েছে সময়জ্ঞান ন্যায়বান. এর বিপরীতে, অধ্যায় আনা কোন অতিরিক্ত সময় আপডেটের প্রয়োজন কারণ সময় নেওয়া নির্দেশ পড়া ক্যাশে / মেমরি থেকে এবং ঘড়ি স্মৃতি একক যে কোড বিভাগে প্রবেশাধিকার পদ্ধতির মাধ্যমে কল করা হয় সঠিকরূপে আপডেট দ্বারা অধীন হয়. এই মত simulator কোড লেখার নিয়ম হচ্ছে যে এক মান রাখা জাভা কোড ভেরিয়েবলগুলি ব্যবহার কিন্তু কি বেশি (বা কম) জন্য ধারণাগতভাবে একটি কৃত্রিম ঘড়ি ব্যবধান পারেন. তারা নশ্বর সংকেত মান মত. কোন সংকেত মান যে এক কৃত্রিম ঘড়ি ব্যবধান অথবা অধিক জন্য বিদ্যমান থাকে হল রেজিস্টার হবে অনুষ্ঠিত. এটা কি CPU1 রান কোড করা হয়. ধারণাগত নশ্বর PC এবং অ মান একাধিক ঘড়ি অন্তর জুড়ে জিম্মা জন্য পিসি এবং এ IR থেকে নাস্তানাবুদ হয়. ' Conf বস্তুর যে দল একসঙ্গে ডিকোড আউটপুট মনেহয় এটা চলতেই থাকে, কিন্তু যত তাড়াতাড়ি এ IR পরিবর্তন পরবর্তী চক্র, conf খুব পরিবর্তিত হবে. সুতরাং ধারণাগতভাবে এটা ঠিক করা হয় এ IR থেকে লাগানো কিছু ডিকোড সার্কিটের মাধ্যমে আপ তার একটি সেট প্রতিনিধিত্ব এবং কোন অতিরিক্ত সংগ্রহস্থল যুক্ত রয়েছে. 'CPU-র উপাদান ক্লাস'এই বিভাগের অবশিষ্ট জাভা ক্লাস যে CPU-র মধ্যে উপাদান প্রতিনিধিত্ব নথি. এটা একটা রেফারেন্স নথি! আপনি একটি অধ্যায় পড়া ঠিক যেমন এবং যখন আপনি প্রয়োজন, এবং না আগে. 'RegisterUnit কম্পোনেন্ট বর্গ'এই উপাদান CPU-র ভিতর 'ছোট এবং সুপার ফাস্ট মেমরি' গঠিত.
ইউনিট রেজিষ্টার একটি অ্যারের গঠিত হয় r এর 32 (আসলে একটু বেশি অর্ডার পিসি PC এবং এ IR পাশাপাশি নিগমবদ্ধ) রেজিস্টার. পড়ুন কিছুই বিস্ময়কর আছে এবং' পদ্ধতি কোড লিখুন. এবং পড়ুন / অথবা লেখার সব যে অথবা হার্ডওয়্যার রেজিস্টার করা যাবে. আর্গুমেন্টের সংখ্যা বলেছেন কিভাবে অনেক রেজিস্টার এবং পড়তে একই সময় (পর্যন্ত দুই সার্চ এবং একটি লেখার, একযোগে সমর্থিত) এ লিখিত হচ্ছে. 'বাইট' আর্গুমেন্ট হিসাবে খাতা সূচকসমূহ জন্য টাইপ শুধু তাই আপনি পাল্টা যুক্তি হল যে হয় রেজিস্টার 5 বিট পাল্টা যুক্তি হল যে হয় রেজিস্টার 32 বিট বিষয়বস্তু সঙ্গে সূচকের গুলান না. হ্যাঁ, আমরা উভয় প্রতিনিধিত্ব 'int' ব্যবহার, কিন্তু পারে তাহলে না দেখতে পারে যা পদ্ধতি টাইপ স্বাক্ষর এ যা খুঁজছেন, এবং প্রোগ্রামিং ত্রুটিগুলি অনুসরণ করা হবে.
কোনো নোট শুধুমাত্র বিষয় ঘড়ি এর স্বয়ংক্রিয় আপডেট যখন খাতা একক ব্যবহার করে. এই গ্যারান্টী বা নিশ্চয়তা দিচ্ছে যে ন্যায়বান সিমুলেশন সময় অ্যাকাউন্টিং এই উপাদান ব্যবহার জন্মাতে পারে. পাঠ্য লিখেছেন একযোগে ঘটেছে. যখন আমরা নিবন্ধন কম্পোনেন্ট বর্গ কোড তাকান, আমরা যে প্রভাব নিতে পরবর্তী চক্র লিখেছেন, দেখুন যাতে এক অনেক স্বতন্ত্র সার্চ এবং একটি লেখার জন্য কি করতে পারেন হবে একটি সফ্টওয়্যার প্রতিটি চক্র, নিবন্ধন ও তা যেন হবে সব চক্র শেষে ঘটেছে একযোগে মধ্যে. |

