English
From jmips
A MIPS processor in JavaThis is the jMIPS easy-to-use open-source MIPS processor in Java. You should already have downloaded the archive (up to date copies are on the sourceforge jMIPS project pages) within which this documentation is to be found as the contents of the doc/html subdirectory.
Getting to know the software greatly improves understanding of the MIPS architecture and creates familiarity with more general concepts of computer systems and architectures. There are several processor models to look at and play with in the archive, identified here as models 1, 2, 3, etc. The numbers increase with increasing sophistication in the model, thus:
The following pages will take you through the process of using and perhaps building the basic processor model in detail, and then go on to consider the other models. The models do not differ in how they are built or used - it's only the innards that are different in each case and that results in one model being faster than another in the same context. You will want to get to work with each model processor in turn, perhaps with the aim in mind of improving the model to get it to run faster still. How long it takes to run overall and per instruction is one of the default printed outputs. If you want to get out statistics such as how long each class of instruction takes to execute in particular circumstances, you will have to add in the code for that yourself. It's open source! You can do that. The code is clearly written and explained in the pages here.
How to run the basic MIPS processor modelThere should be a Java archive file (a jar) in the supplied zip archive or compressed tar file (get one of them from the download link on the jMIPS project page). If there isn't, then go to the next section. You should extract the jar file from the archive with (for example, the archive name depending on your download choice) % unzip jMIPS-1.7.zip jMIPS-1.7/lib/CPU.jar or % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/CPU.jar Also extract some of the contents of the misc directory with % unzip jMIPS-1.7.zip jMIPS-1.7/misc/hello_mips32 or % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/hello_mips32 then the Cpu1 class can be run by a Java Virtual Machine (JVM) on any platform. You might do so under Linux with % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 For example: % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 Hello world % If you are unpacking the 1.7d or later archive, you'll get a GUI to launch the five pre-built models with. Run % jMIPS-1.7d/lib/CPU.jar % 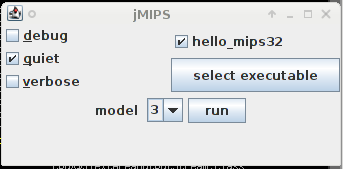 and you'll get the window shown at right. It's already been used to pick out a hello_mips32 executable file from the misc/ subdirectory of the source archive, so that's shown as available and by default ready to run; and the "quiet" switch has already been selected too! To change the CPU model (set at "3" in the image), use the "model" control. Then hit "run" and a window will pop up containing the output from the run. (If you'd like to see a really exciting UML
"activity diagram" for a user interacting with
this GUI, just click on this little icon: How to compile the basic MIPS processor modelIf you want to or have to compile the Java source code to get executable code, you would do so as follows, depending on which tools you have available. Since there are different sets of tools that people are used to using on different operating systems, the following subsections are specific to an operating system. Compiling under Linux or UnixIf you are on a Mac, and use a HFS or HFS+ format file system, go into the system properties and turn on case sensitivity for it. You will need that as otherwise you will get case folding bringing several file names into collision with each other, which you do not want. Unarchive the zip or compressed tar file (get them from the jMIPS project page download link) with % unzip jMIPS-1.7.zip or % tar xzvf jMIPS-1.7.tgz respectively. Then find the src/ directory in the newly unpacked file hierarchy and change your current directory to it (use the cd jMIPS-1.7/src change directory command to do so). I prefer to produce generic Java bytecode for a Java Virtual machine (JVM), with % javac CPU/Cpu1.java in the src/ directory, and then the resulting Cpu1.class file can be run by a JVM on any platform. You might do so under Linux with % java CPU/Cpu1 -q ../misc/hello_mips32 For example: % java CPU/Cpu1 -q ../misc/hello_mips32 Hello world % Building a jar file is just a question of first building all the java class files:
% javac CPU/*.java % and then making a jar file with % jar cf ../lib/CPU.jar CPU/*.class % In reality, a jar is just a zip archive of the package done without compression, and with one extra manifest file also included. So you can make it using just a zip archiver and you don't necessarily need the jar tool. Look up the details on the Java tutorials site or examine an existing jar file using the zip archiver for comparison. Compiling under WindowsTo import the source into a Java NetBeans IDE, start yourself a new NB project (called `jMIPS', presumably), making sure the IDE dialog's tick-boxes for `Main Class', etc, are all unchecked. Once the IDE has built all the directories and
control files that it needs, copy the src/CPU/
directory *.java files from the source
code archive to a new src/CPU/
subdirectory of the jMIPS project directory that
has just been created by NetBeans. Use an
operating system copy command straight from inside
the zip archive to avoid the files touching disk
on the way. Windows will fold the
CPU2.java/Cpu2.java file names into collision
otherwise. If Netbeans has a menu choice to import
from zip, or compile from zip, that
would be perfect. Eclipse does have that option. The IDE will detect you populating the source code area and it will expand its `Source Packages' tree view (the jMIPS/src directory) to include a CPU "package" and its Java files. If you'd rather, you can systematically rename the java class files for each processor model from Cpu1.java, Cpu2.java, etc, to, for example, WinCpu1.java, WinCpu2.java, etc. You will have to rename the class declared within each file to match. Notes on running a processor modelThe meaning of the command line options is as follows:
% java CPU.Cpu1 hello_mips32 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) 3: 0.000000024s: 0x8003008c: addu $30, $29, $0 4: 0.000000030s: 0x80030090: sw $28, 16($29) ... 218: 0.000001567s: 0x8003000c: lui $3, -20480 219: 0.000001573s: 0x80030010: ori $3, $3, 16 220: 0.000001580s: 0x80030014: sb $3, 0($3) % This run executed 220 instructions in 0.000001580 simulated seconds (the clock rate is 1 simulated GHz). That was around 5 clock ticks per instruction execution.
% java CPU.Cpu1 -q hello_mips32 Hello world %
% java CPU.Cpu1 -d hello_mips32 text start at virtual addr 0x80030000 file offset 0x10000 text end at virtual addr 0x800300e0 file offset 0x100e0 text entry at virtual addr 0x80030080 file offset 0x10080 read 224B at offset 65536 from file 'hello_mips32' stack start at virtual addr 0xb0000000 stack end at virtual addr 0xb0100000 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) ... %
Please do just edit away at the source in order to add anything else you like, add yourself to the credits list at the top of the source code in the file, and send in your changed code - or publish it yourself elsewhere, as you wish. Producing MIPS machine code to run in the processorThe "Hello world" program ready-built in MIPS R3000 machine code is in the archive as the hello_mips32 file in the misc/ subdirectory. The (C language) source code for it is in the hello_mips32.c file in the archive misc/ directory, and the MIPS assembler for it is the hello_mips32.s. The machine code has been compiled quite standardly from the given source to give the machine code, via % gcc -static -o hello_mips32 -Wl,-e,f hello_mips32.c on a real MIPS machine. Check the manual page for the gcc command (i.e., "man gcc") to find out exactly what the options given in this command line mean. On non-MIPS but Unix platforms, the following should achieve the same result using the mips-gcc cross-compiler suite (you may typically have to run a "setup MIPS" command in your shell environment in order to set your executable search path to pick up the cross-compiler's component parts):
% mips-gcc -DMIPS -mips1 -mabi=32 -c hello_mips32.c % mips-ld -Ttext 0x80003000 -e f -o hello_mips32 hello_mips32.o The software model of a MIPS processor stands in handily for a real MIPS machine when running the "Hello world" machine code. % java CPU/Cpu1 -q hello_mips32 Hello world However, more complicated machine code involving interrupts and peripherals might defeat this model.
Getting into the source codeHere are suggestions for how to get yourself "into" the source code, and having fun.
Edit it, credit yourself at top, and send the changes to the project. This is generally a good way to go about getting to know code. Complain about how badly written and difficult to understand it is, and fix it. You'll find copious notes on the code in the following section. You will want to look at the code with those notes in hand. The notes will prove most helpful in terms of understanding the large-scale features, leaving only nuances to be explained via source code comments.
First check on the web to see what the instructions do and what the machine code format for them is! One can say they must be a cross between a branch instruction and a jump-and-link instruction just from the name. Suppose bgezal is much the same as bgez but in the event of a successful test it does the same as a jal instruction does (places the address of the following instruction in the return address register, ra). That is useful for implementing a conditional subroutine call. Check google!
Test your modified emulator on the modified machine code. You'll need to make a compensating change to the program in order to save and restore the $ra return address register around the branch, but you'll see the new branch instruction itself working. Notes on the basic MIPS processor model codeThe regularity of the MIPS instruction set architecture results in very transparent simulator code. The simulator code has also been written with the objective of producing code that is clear without being over-sophisticated. 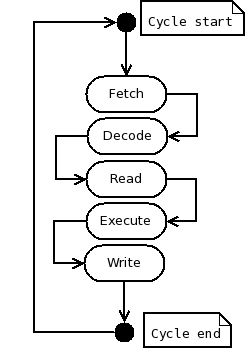 As a result, you can check out what any MIPS instruction does by eyeballing the appropriate area of the code. The CPU1 class code is imperative with just the minimum of object-oriented wrapping in order to make it easy to walk through. It's a state machine! And so it is, in reality. Whatever you need to see in order to understand the CPU1 processor model is in that code in the CPU1 class, and you need look nowhere else. You'll see there's just one big while loop in the code. It runs the generic Von Neumann fetch-decode-(read data)-execute-(write data) cycle (see accompanying figure at right), as implemented in all mainstream processor designs since the 1940s, and all the action is embedded inside this one long loop, with one short contiguous part dedicated to each kind of MIPS instruction. So you'll find there are about 10 or 12 shorter contiguous sections making up the body of the loop. For example, the part dealing with jump instructions looks like this ('fetch' has already been done at the start of the loop body, in order to read the next instruction into the IR register). It's mostly block comment:
That's just 6 lines of real code, not counting the comment lines. In summary, the model encoded by the CPU1 class embodies an abstract Von Neumann processor design without low-level details of precisely how the electrons are being shuffled around and you should have no problem at all in looking at the code and understanding what it does as hardware (tip: when you look at a small section of any source code, look at it with a particular question in mind, such as figuring out how function X is used so you can make use of it yourself, and ignore everything else; repeat until done). The difference with respect to real hardware is that this code can only do one thing at a time, whereas real physics results in hardware doing all these things done in sequence here all at the same time during a processor cycle. However, execution is timed using the Clock class methods and the final accounting to you of what has happened only occurs when a complete processor cycle is up. So the order things are done in in software between those points does not particularly matter. So long as the order makes logical sense, the model works. For example, the jump code above writes the RA register with data read from the instruction in the IR register. In real hardware, those two things happen simultaneously, as the result of an electric potential field transmitted across a conductive wire. In the code above the read happens before the write, because the Java implementation requires it that way! We can't write in Java "read A and write the result into B simultaneously". The physics of the real universe makes that easy in reality! The accounting by the components involved, however, will record the same simulation time moment of occurrence for both the read and the write, and that is all you will see in the end. Class layoutThere are the following top-level classes in the source code, all in all. Only the first five or so contain any code worth discussing, and the discussion follows below the table:
This is a so-called domain-model design. The classes in the software code correspond to real physical components in the hardware MIPS processor. The methods correspond to actual physical operations that the hardware components can do. Virtual operations, such as those that can be composed as combinations of simpler operations, are never implemented in the software no matter how "convenient" it might seem, as they have no physical existence. 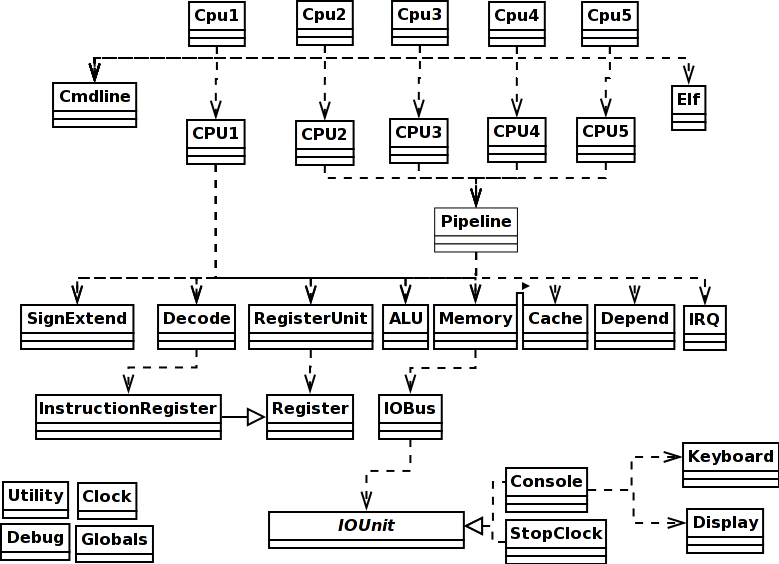
The class diagram at right shows the dependencies. If you want to add a single-step facility to the Cpu1 simulator, you need to take the single big fetch-decode-execute while loop in the CPU1 code and make it pause for user input before each new cycle. You should make an s ("step") from the user execute another cyle; a c ("continue") should send it back to cycling continuously; a p ("print") and a register number or memory address should show the register or memory contents; a d ("display") should be like print but cause the printout to occur at every step. The main routine in Cpu1This is a quick and dirty precis of the main routine in Cpu1, the wrapper class whose job is to understand the Java command line arguments you used, and then set the CPU1 processor model going:
You see here that main parses the command line using the Cmdline analyse method, obtaining a list of executable files whose code it will run. The executable files are in what is known as `ELF format'. ELF is a cross-platform standard used in many operating systems in use today and it is the format produced by the gcc MIPS compilers and assemblers. The main routine then goes ahead and loads those ELF files. That is, it calls the Elf constructor on each file name, which parses the contents of the file and extracts information such as entry points, intended virtual address locations, etc., all of which get placed in the resulting Elf object. Then main builds the stack region of memory and the CPU, and tells the CPU's memory unit about the stack and its intended virtual address via a call to the memory unit's addRegion method. And it tells the memory unit about the various stretches of program code it has picked up from the ELF executable files via more calls to addRegion. It remains to set the CPU's SP (`stack pointer') register to point to the top of stack, set the CPU's PC (`program counter') register to the address of the intended program entry point - obtained from the first file named on the command line - and then call the newly built and prepped CPU's run method. That's all. So the following is all the programmer needs to know about Cpu1:
The next section shows you what the 'runs it' means. The CPU1 processor modelThe following is all the programmer can see or needs to know about the CPU1 processor class. There's a (pretty skeletal) constructor, and one method.
As it says in the comment, the loop contains the interior of the fetch-decode-execute cycle. Here it comes:
The abstract fetch/decode/(read)/execute/(write) sequence is clearly visible in the code. There's one conditional block dedicated to each kind of instruction (i.e., one per distinct opcode). The fragment above shows the block dedicated to treating ALU operations, which all have the opcode 0. The different kinds of ALU operation are distinguished by different values of the func field in the instruction (the last 6 bits at the least significant end of the word in bigendian layout). All the distinct fields of the instruction in the IR are broken out, including func, in the section labelled DECODE!, and then the instruction's functionality is implemented in the short Java code sections labelled READ!, EXECUTE!, WRITE! What's acceptable and what's not acceptable code in a processor modelNote that the code in the CPU1 run code is conscientiously using the emulated CPU hardware to do all the work. Instead of adding 4 to the PC value using the power of the Java programming language ("pc += 4"), for example, the FETCH section reads the PC using the PC register object's read method, adds 4 using the dedicated fetch adder's execute method, and routes the result back to the PC using the PC register object's write method. That's a long way round where "pc += 4" might have done the job! What's going on! What's allowed here and what's not? It is acceptable in the Java model to label values output by a hardware unit and use them as inputs to other hardware units. We've done that with 'pc = ...' and '... = pc'. That sort of thing amounts to using simple wiring to connect the data signals through the CPU circuitry within a single clock cycle. That's alright. But anything even as substantial as a +4 on the 'pc' would be cheating to do in Java because it takes time and circuitry to do it in real life. The Java objects standing in for the CPU hardware components (alu, register_unit, etc) have timing embedded in them and using them in the Java code makes the simulated clock advance correctly. They're OK to use for computations. Computations take time to do in real life. The Java objects methods advance simulated time. All OK. Using Java code like "pc+=4" would magically achieve the required effect without taking any simulated time and not occupy any of the simulated hardware in doing it either! That's not emulating the real life situation, that's emulating magic. Not OK. So any arithmetic has to be done using the Java objects representing CPU hardware components, not Java arithmetic. Because the DECODE section is done explicitly in inline Java code here, which makes it seem like it takes no time at all to do in simulated time, an explicit clock update has been embedded at the end of the DECODE code in order to keep the simulator timing honest. Contrariwise, the FETCH section needs no extra time update because the time taken is dominated by the instruction read from cache/memory, and the clock is updated properly via the memory unit access method call in that code section. The rule in writing simulator code like this is that one can use Java code variables to hold values but for no more than (less than) what is conceptually one simulated clock interval. They're like transitory signal values. Any signal value that is to persist for one simulated clock interval or more must be held in registers. That's what's done in the CPU1 run code. The notionally transitory pc and ir values are routed to the PC and IR for safekeeping across multiple clock intervals. The conf object that groups together the decode outputs looks like it persists, but as soon as the IR changes next cycle, the conf will be changed too. So it's conceptually just representing a set of wires hooked up to the IR via some decode circuitry and there is no extra storage involved. The CPU component classesThe remainder of this section documents the Java classes that represent components within the CPU. It's a reference document! You read a section just as and when you need to, and not before.
The RegisterUnit component classThis component comprises the 'small and super fast memory' inside the CPU.
Register units are composed of an array r of 32 (actually a little more in order to incorporate PC and IR as well) registers. There is nothing surprising in the read and write method codes. Read and/or write is all that can be done by or to hardware registers. The number of arguments says how many registers are being read and written at the same time (up to two reads and one write are supported, simultaneously). The 'byte' type for the register indices as arguments is just so you don't confuse the arguments that are the 5-bit indices of registers with the arguments that are the 32-bit contents of registers. Yes, we could use 'int' to represent both, but then you couldn't see which was which looking at the method type signature, and programming errors would follow on.
The only thing of any note is the automatic update of the clock when using the register unit. That guarantees that using this component leads to honest time accounting in the simulation. Reads and writes happen simultaneously. When we look at the Register component class code, we'll see that writes take effect next cycle, so one can do many distinct reads and one write to a register each cycle in the software, and it'll look as though it all happened at once in the simulator at the end of the cycle. The ALU classThe ALU component does the arithmetic within the CPU.
The ALU class is a substantial piece of code, but it's entirely simplistic. The execute method code consists of a large switch statement which chooses a short block of code to execute depending on the func (function code) value supplied as argument. The code combines the two input integers a and b in the appropriate way to produce the result c and a carry or zero indicator z:
The above illustrates only the addition operation code, but it is perfectly representative. None of the ALU code is any more complicated than that. The Memory component classThe Memory component represents random access memory (RAM) as seen by the CPU. The implementation here really mashes together two real hardware components, the memory manager and the memory units. It would be a bit of fussiness to separate out the two as two different components here, because we're not concerned with modeling memory in the same detail as we are modeling the CPU, and we would rather look at memory for the moment as a shiny, smooth, black box.
A memory object internally consists of an array of regions. These really exist as 'zone boundaries' configured into the memory manager side of our memory unit. Each region consists of a first address in memory, a last address, and a sequence of bytes representing the memory region content. In real life, once configured (and the configuration changes on the fly as one process after another enters the CPU), the memory manager imposes different policies on the different regions. One region may be read-only, another may be read-write. One may be cached, another not. The addRegion method is used to configure one more region into the memory unit. The read32be method then simply cycles through the array of regions looking for one which contains the supplied address for lookup, and returns the data stored in the region at the supplied offset when it finds the right region. The write32be method is complementary:
One might eventually want to signal an exception when a missing (i.e., unconfigured) region is addressed, but right now this code does the simple thing and ignores the problem. The memory unit also contains special read8 and write8 methods which read and write only one byte at a time. While they might seem like a convenience only (and indeed, internally they read and write 4 bytes at a time when they can using the read32be and write32be stalwarts), their real use is in performing memory mapped I/O. When the address supplied is right, the memory unit read8 and write8 methods pass the access attempt on to an iobus instead of to memory. Behind the bus and attached to it lie several I/O units. The code will be described in more detail below, but the most relevant thing to take in right now is that this arrangement means that talking to a special memory address allows characters to be read from the keyboard and printed to the screen. It's called memory-mapped I/O. The way the iobus intercepts are implemented inside the memory unit code is like this:
"0" is the I/O bus address of the console keyboard input, and "1" is the I/O bus address of the console display output. Via these intercepts, the memory unit translates reads from memory address GETCHAR_ADDRESS to reads from I/O bus address 0 which the bus translates to reads from the console attached to it. Similarly for PUTCHAR_ADDRESS and writes to the console. The memory unit's read8 code is more accurately represented as follows, with a loop over a port list instead of the hard-coded if statement address matches shown in the text above:
We could get away with adding a single port at a single memory address for the console unit, but I've preferred to cater for the general case in which PUTCHAR_ADDRESS and GETCHAR_ADDRESS are not necessarily the same, thus registering two different port addresses which give access to exactly the same console in exactly the same way. It's not a significant waste. It often happens in real life that I/O units have several alternative address mappings, all of which can be used for access. The redundancy is sometimes useful, and is often mandated for reasons of backwards-compatibility. The port list is appended to within the memory unit like this: port.add(new Port(GETCHAR_ADDR, 0)); // translation GETCHAR_ADDR -> bus 0 added port.add(new Port(PUTCHAR_ADDR, 1)); // translation PUTCHAR_ADDR -> bus 1 added In a later iteration of this code, you may wish to allow certain ports to be designated READ_ONLY or WRITE_ONLY! For now, each port is expected to support both reads and writes. Timing: raw access to memory is set to take MEMORY_LATENCY picoseconds, by default 2500, i.e., 2.5ns. You can change this value by fiddling with the MEMORY_LATENCY static variable in the Globals class. Or you can use "-o MEMORY_LATENCY=..." on the command line. Access to the I/O devices through the I/O bus address mappings takes a shorter time, nominally CACHE_LATENCY, which is set by default to 1000 picoseconds, i.e. 1ns. The idea is that on write all that happens is that the data is launched onto the I/O bus and then the CPU continues with its cycle. The I/O bus works on its own to send the data on to the printer (say), and the printer works on its own to buffer the data, and later print it out. On read all that happens is that the keyboard (say) device buffer is read via the bus for any characters previously typed. The ink is not sprayed on the paper, nor the keypress executed within the 1ns period itself. But how does the CPU cope with delays of the magnitude of memory acceses? They are longer than the nominal 1ns associated with the default clock rate of 1GHz and at least on read the memory access must take place fully within the CPU clock cycle. The answer is that the CPU executes a single exceptionally elongated cycle for a main memory read or write. The elongated cycle is of fixed duration but of such a length that the memory is able to respond within it. It's 2.5ns long, corresponding roughly to memory that can deliver 400MB/s. That's less than half as fast as L1 cache (which you'll meet in the CPU4 design). You will have to wait until you meet the CPU5 code to be able to improve on this design. The IOBus component classThe IOBus is part of a three-way communication between CPU, memory, and it. When the CPU addresses certain places in memory, the access is redirected my the memory manager part of the memory unit to the IOBus instead. The IOBus class read8 and write8 methods take a bus address ("0", "1", etc.) instead of a memory address. The redirect substitutes a bus address for a memory address. There's an addIO method which registers an I/O unit (e.g. a Console object) onto the bus, which gives it a bus address. The bus addresses are awarded in order of registration to each I/O unit that wants one, in turn. As the CPU and memory unit is being put together, the bus is built and a single console is registered to the bus at both of bus addresses 0 and 1 like this: IOBus iobus = new IOBus(); Console console = new Console(); short stdin = iobus.addIO(console); // console registered as bus addr 0 short stdout = iobus.addIO(console); // console registered as bus addr 1 also Bus address 0 will be the mapping used for GETCHAR_ADDRESS within the memory unit, corresponding to reads from the console, and bus address 1 will be the mapping for PUTCHAR_ADDRESS, corresponding to writes to the console. The full interface to the I/O bus methods is
IOUnit is an abstract class ("interface"). Console objects match that interface. To meet the requirements of the interface an object just needs to have read8 and write8 methods. These methods don't take an address at all as they are conceptually associated with just their own I/O unit:
An IOUnit produces a byte on a read request, and absorbs a byte on a write request. Console objects in particular have these methods. The memory unit build code adds a console to the iobus and maps its bus address to a memory address via the port list. The upshot is that the console object is accessible over the iobus via memory mapped addressing from the memory unit. Why have we gone to the trouble of introducing a bus to mediate between the memory unit and what is at the moment a single I/O unit, a single console? It's really so that we can model delays introduced by the fact that the bus can only be used to access one I/O unit at a time, and only one byte at a time can travel down it (in one direction at a time), and the fact that the I/O bus in real life is relatively slow too - 33MHz, as compared to the CPU's 1GHz. The CPU can execute 30 instructions in the time that it takes 1 byte to travel down this I/O bus. If the memory unit tries to access the bus while it is already in use, there's trouble. Make sure that writes to the I/O bus are at least 30ns apart or you will find that trouble and strange things will start to happen like writes to the bus being discarded. In practice, it's not a deal-breaker. Whatever machine code you write, it's almost unheard of to produce a loop tight enough to do two writes to the I/O bus within 30ns. The CPU1 design struggles to deliver 6 machine instruction executions in that time. That's not enough to save registers, run a jump to a subroutine, do something, jump back, restore registers, increment a loop counter, check a loop bound, etc. There's code in there that makes a noise on the simulation error stream if the I/O bus ever gets swamped and it does not happen in practice. It could, though. For fun, try making it happen, by writing the appropriate machine code (via MIPS assembler, of course). You'll get a stream of imprecatory complaints on the screen. Real CPUs have their limits too, and real programmers write to them. You can write nearly anything you want in assembler, and whether the metal underneath can respond as you intend or not is a subtly different question. Real programmers follow the maxim of don't do that then. For example, if you check real MIPS assembler code you'll find that every jump instruction is followed by a NOP because nearly every real MIPS machine's pipeline and instruction prefetch mechanism makes it inevitable that the instruction after a jump will be executed! Miserly programmers could in theory save program text space by directly following a jump with a labelled non-trivial instruction, but they don't, because they know what will happen. Evolution has taught real programmers (the ones that survive to get their next paycheck and eat their next lunch) that reality is stronger than theory. Compilers don't do that then either, for the same reason. The StopClock component classOne more special I/O address mapping intercept is pre-set. It causes the Clock.stop method to be called when HALT_ADDRESS is written to, which ends the simulation!
There's really a special extra I/O unit called stopClock placed on the I/O bus to implement this. If you check out what the Memory code really looks like in the source file, you'll see instead of the above something like the following in the memory unit setup code: StopClock stopClock = new StopClock(); short stpclk = iobus.addIO(stopClock); // stopClock registered as bus addr 3 port.add(new Port(HALT_ADDRESS, stpclk)); // translation HALT_ADDR -> bus 3 added And the StopClock write8 method is only a thin wrapper round that vital call to Clock.stop.
If you are going to build more I/O units to implement special effects (perhaps audio?), the stopClock example provides you with the model for the way to go about it: first code the unit as a class with methods write8 and read8 that really do whatever you want, then make a new instance of the class at CPU or memory build time in the CPU code and put in a registration call with iobus.addIO for it, finally add a memory mapping intercept into the memory unit code. For best results do that last by updating the port list in the memory unit using port.add. The Register component classRegisters are the components within the CPU that remember. Everything else starts each processor cycle as though it were starting anew each time. A register remembers what value it had last cycle. 32 addressable registers (and a few more) make up the register unit component in the CPU.
Register objects protect a single internal integer value. In principle, read and write methods simply access the integer, like this:
However, there's a twist. To better mimic the action of a real, clocked, register, we've arranged that the result of a write cannot be seen until the next clock tick. That is, reading the register shows the value stored in the register as of the last clock tick. You can write the register and read the register as you like during the period of a single clock tick, but reading will always show the same old value. After you call Clock.sync then reads will start showing the value that you wrote last before the Clock.sync call. To implement that we've added a variable xtick that holds the number of the clock cycle on which the current value of x was written. There's also a variable xnext that holds the value inserted by a write call. Reading simply returns x if the current clock cycle is still xtick, otherwise it moves xnext into x and updates xtick, before returning x.
To make sure that the initial settings of the PC and SP registers in the main routine at CPU start-up are effective, xtick is initialized to -1. Then on clock cycle number 0 the PC is written, which sets xnext. But on the first read in the fetch part of the fetch-decode-execute cycle, also on cycle 0, xnext will be moved into x and returned by the read. It's a trick, but it works. Setting PC and SP in main makes those values available in the 0th processor cycle. The SignExtend component classThe SignExtend component is the unit within the CPU that changes a 16-bit number into a 32-bit number, preserving sign in the process. In other words, it does not simply extend to the left with 16 zero bits.
The sign-extend object's one and only method extends a 16-bit half-word to a 32-bit full-word while preserving sign. Fortunately, in Java, that's just achieved by a (here implicit) cast to int. So the Java code is as trivial as can be!
There's nothing more to say (in Java). Of course, somebody looking with a debugger at the hardware will see a negative 16-bit number being extended to the left with 16 1s, not 0s. The Console component classThe Console component implements the IOUnit interface of read8 and write8 methods. It's a thing that inputs and outputs characters, reading from a keyboard and writing to a screen.
A Console object's methods use the Java System.out.print and System.in.read methods to move a single byte to/from screen/keyboard.
On input, if no character is in the keyboard buffer, the read8 method returns 0. The fast timing encoded in the routine reflects the immediate nature of this behaviour. The CPU is polling the keyboard input buffer. There's a character in it or there is not. On output, there is a finite screen buffer to consider. All the CPU does is place a character in the screen output queue, which is immediate. It's the console that has to slowly pass the characters in its queue out to the screen. If the CPU writes to the queue faster than the console can empty the queue to screen, then characters soon start being lost because the CPU does not pause! The characters that are lost are the last ones that the CPU attempts to place on the already full screen output queue. They go nowhere. All that results in quite complex timing emulation code in the write8 method. It's not reproduced above. But beware! This console unit will eventually lose characters if you attempt to write through it to screen too quickly for too long at a time without allowing it to drain. You won't find a cure for that until you look at the CPU5 code. We've actually been kind and supposed that the Console is fast enough internally to be able to see every character passed to it by the I/O bus. It's another question as to whether it will queue, output or drop the character, but see it it will. It might have been the case that the I/O bus were considerably faster than the Console's internals. Let's not go there! Slow printers are enough of a pain as it is. The CPU5 code will allow you to deal with that problem. The InstructionRegister component classThe InstructionRegister class encapsulates the decode combinatorial logic. Its numerous methods break out the fields from a machine code instruction of the appropriate kind, but there's nothing at all complicated or subtle about the way it's done.
The methods are all one-liners.
There are about 20 different decoding methods, all similar to the above. The best thing to do is to skim-read the source file and become aware of what there are but look up what they are called only when or if you need one. The global ClockNotice that there is only one of this component. All its methods (and its internal attributes) are marked static, meaning that there's only one.
The global clock encapsulates a single 64-bit number representing the number of picoseconds t elapsed since startup. The increment method changes the value, returning the old value. The running method returns the boolean value true until stop has been called, after which it returns false. In addition to the global internal picosecond counter t, the clock maintains a sense of when the last whole clock cycle started and when it is due to end, which could be at virtually any picosecond value. The reset method sets t back to the current cycle start and the sync method sets t to the current cycle end/next cycle start point. The idea is that calls to increment advise the clock of delays introduced by CPU circuit elements within the current clock cycle. Since the elements (ALU, registers, etc.) are arrayed in parallel all the increment delays notionally happen in parallel. So they are not cumulative. Instead the effect of increment is to push the time t towards the maximum of all the delays within the current cycle announced via increment so far. Come the next call of sync the value of t will be checked against the next clock cycle start point and if t has overrun a nasty message will be displayed on your screen and the CPU will break down and stop, reflecting the idea that we have been running the CPU clock too fast for the CPU components to be able to keep up with it. Helper classesThe following sections detail a few extra classes which do not represent CPU components. They're there just to give Java a helping hand.
The Utility routinesThe Utility class contains a swathe of leftover routines that are generally helpful and don't belong anywhere else at all. They are static. That is, they don't have any access to any local objects's attributes. They're just pure functions.
These utility routines are the stuff of elementary Java exercises, and you may wish to reimplement them to suit your own style preferences.
The Cmdline routinesThe Cmdline class wraps some common code that is used to help parse command-line options and arguments.
While the command line parse routines are really quite complex codes internally, they only implement the very well-known API for the GNU getopt library call. Look up getopt(3) using the unix man[ual] command. It's implemented as a private static method here and called repeatedly by analyse until the command line is exausted.
The counter optind (index into the array of strings argv passed from main) is incremented every time getopt is called and opt (a short code for the option parsed) and optarg (the string representing the option's argument, if any) are set by the getopt call. I've skimped on implementing more of the standard getopt functionality than I needed. In particular, my hasty implementation doesn't bother to reorder the command line so that the non-option arguments come last. In consequence, you'll have to use a command line like "CPU/Cpu1 -q hello_mips32" instead of being allowed to write "CPU/Cpu1 hello_mips32 -q" at the command line. All the options have to come before all the non-option arguments. That's something to apologise for sorry and you may wish to fix that lazy oversight which is currently spoiling the implementation of getopt. The Elf helperThe Elf class is there to hide all the messy business of picking up an executable file from the file system and reading its machine code contents into memory. You really do not want to know about it.
The Elf class code is complex internally, but all it does is hack its way through an ELF-formated file picking up data as it goes. Everything needed and more than you want to know about the ELF format standard is to be found in the unix elf(7) man[ual] page and the elf.h C header file on any system with a working C compiler. The Java code has been commented quite heavily. ELF files consist of a header followed by several segments. Each segment is made up of sections. The ELF header consists of a fixed format initial part and a variable length trailer. The fixed format initial part of the header defines the sizes and numbers of the entries and the offsets to two tables farther on in the trailing part of the header. As far as one can see, the header is in practice 64KB long in total, even when the data it contains is relatively little. It may be possible that it is sometimes longer than 64KB. The total header size is one of the more important bits of information in the fixed format initial part of the header! The first table in the trailing part of the ELF header enumerates and describes the segments in the ELF file. It's called the "segment header table". The Java code searches that table looking for a segment that is read-only and executable. There appears to be only one such segment in all ELF files in real life, but perhaps there can be more. This is the segment that contains the program code part of the ELF file. This so-called program segment should contain both a program section, and also a read-only data section, and there usually is at least one of the latter. It'll contain the manifest string constants used within the program, for one thing. But the code doesn't bother with the distinction between those two sections within the program segment. It arranges that the whole of the program segment, containing both program instructions and read-only data, be lifted into the Elf object as a single byte array. Fine distinctions as to which part is which here are lost. The segment header table in the ELF file lists the offset in the file and the length of the program segment. It also lists the virtual address that it is supposed to be loaded into memory at for the purposes of running the program code successfully. That's all information which is lifted into the Elf object by the parse. The ELF header also contains the intended entry point in virtual address space for the program, and that also gets lifted into the eventual Elf object. The code does not check for consistency, and you may wish to add such a check (One would hope the entry point address were within the area in memory where the supposed program gets loaded to!). The code essentially blithely ignores the second table in the ELF header, which lists the sections (the sub-parts of the segments), and which therefore potentially gives up more fine-grained information than the segment header table. It's called the "section header table". Ignoring this table may be fatal in some situations. In particular, the section header table provides a pointer to an area of the ELF file where the names of all the segments and sections are kept, and that's potentially a much more reliable way of locating the program segment/section than the way it's done now. The program section name is always ".text". Check the elf(7) manual page for more details. However, parsing the name table itself is not at all simple, once one has found it, and the Java code does not try! If one does parse it then in particular one also has a reliable way of finding a ".bss" segment, if there is one. If it exists, that defines a range of memory addresses which are supposed to be zeroed and provided to the program to serve as writable scratch space. These bss sections are quite common in compiler output. Any variable declared static in C will be in one. The code does not even attempt to look for it, so if a program has a bss segment, the simulator will fail when it runs and doom and gloom will descend on the multitudes ... A hack that may find a bss segment with little work may be to look for one that is described as writable and not executable. It's hard to imagine another with those two characteristics. Please add a search for such a section and prepare a corresponding memory area in the simulator runtime. And while the code assumes that a read-only program data section would be found in the executable program segment, that's also only a guess which may turn out not to be true of some executable files out there. Please add some checks which make a loud noise if the assumption is proved incorrect and there are read-only sections elsewhere. So there's lots of room for improvement here, but it's tangential to the issue of whether the simulator itself works or works well on those executable program files it can run. NB: Many of the potential issues mentioned may have been resolved by the time you read this. Check the code! The Debug class
There is no code of relevance to understanding how a CPU or the CPU simulation works to be found among the Debug routines! Simple unoptimized pipelined processor modelRunning the CPU2 modelIf you have the jar file from the distributed archive, you should be able to run the bytecode directly with java -cp lib/CPU.jar CPU.Cpu2 misc/helloworld_mips32 The Java source code is in the Cpu2.java file and if necessary (i.e. the jar file is missing or damaged) you can compile it with javac CPU/Cpu2.java from the src/ directory of the unarchived distribution. That will produce bytecode that you can run with java CPU.Cpu2 misc/helloworld_mips32
Internally, however, the CPU2 code is much more sophisticated than the unpipelined code in CPU1, and not as useful to walk through, though you may do so.
What's new?The major differences in the pipelined code with respect to the unpipelined code are that The single fetch-decode-execute cycle loop in the unpipelined code has been decomposed into separate Fetch, Decode, (Read), Execute (and Write) components ("stages"), corresponding to the commented note about where each stage starts and ends that you can see in the unpipelined CPU1 run code (e.g. "// write"). Here's a diagram of the pipeline that has been implemented:
Notice that the pipeline contains extra little registers (I'll call them "holders") which hold the inputs and outputs from each stage for passing on to the next. The pipeline is a physically manifested pipeline, in other words. The "holders" are like laundry baskets in which the laundry is kept before passing it on from the washer stage to the dryer stage in the laundry room - it's not just a question of shovelling the laundry out of the washer and into the dryer directly. Laundry baskets and holders both allow for some minor hold-up in the work-flow. To clear the washer for another load you don't have to have the dryer already clear - you can put the laundry from the washer into the basket instead. The input basket/holder for the next stage is the output basket/holder from the previous stage. There's a fairly boring list of names of pipeline stage input and output holders that you'll need to get used to eventually. They're shown in the diagram above. I'll work through the list below, and you can skip past it for the moment if you aren't interested.
You'll see this implementation mechanism enumerated in the codes below. It's simply the easiest way of calculating in a single thread how the parallel hardware behaves. One has to choose to do one part of the calculation before another. There follows the list of all the new Java classes and their methods. The pipeline ("Pipe") component classInside the CPU2 processor, you'll find a conceptual aggregation of most of its components into a pipeline. Because the pipeline has no physical existence outside of the CPU, it is implemented as an interior class in Java, to signal that "this is not real". It's a concept in the mind of the designer, so the public can't have access to it. It's not a public class. Only the CPU2 object knows it's there, and makes calls to it (and even then, it has just one thing to say to it: "tick", please!).
The pipeline's tick method is implemented internally like this:
Certain trickery with the clock to get the parallel execution time-wise accounting right is shown as commentary here. In the real code it's a call (to "Clock.reset()", funnily enough). The Fetch component class within the pipeline"Fetch" is the first stage of the pipeline in the CPU. It's there to get an instruction into the IR ("instruction register"). Afterwards the instruction will be worked on in subsequent stages. It's a factory assembly line! The component is again an aggregation or way of making work together of other units that already exist within the PC, so it is represented as an interior class within an interior class in Java! It's a 'concept class', an interior class within the interior class that is the pipeline class within the CPU code. Only the pipeline object knows about this object class - it's a figment of a pipeline's dream, which is itself a CPU's dream. Non-philosophically, however:
The Fetch stage tick method Java code collects together the statements found at the start of the while loop in the CPU1 run method:
There's just one bit of trickery that needs mentioning here. A jump or branch instruction ahead in the Write stage of the pipeline usually alters the PC. Normally that change would not be seen, reading from PC, until the next tick of the clock comes round. Registers show what has been written to them last clock tick on the next clock tick. That means that one would normally expect the Fetch stage to be prefetching rubbish that will almost certainly be jetisoned next clock tick while a branch or jump is being treated in the Write stage. While that is nothing that will hurt the functionality of the pipeline, it is inefficient (it slows things up), and worse, it means having to tolerate rubbish instructions that may mean nothing at all and be improperly formatted in the IR register. The address from which the instruction is prefetched may not even be in the range of the program text, but from one instruction beyond. It's a fair can of worms. There is a simple way to avoid it, and that has been taken in the code. Changes in the PC made in the Write stage are forwarded immediately to the Fetch stage, thus avoiding any spuriousy prefetched code in the IR alongside a branch or jump in the Write stage. Concretely, the PC is only consulted for the pc value in the Fetch stage when the Write stage is not dominating the PC. In case there is an instruction in the Write stage the conf4 holder will contain data. In case the instruction is a jump, or a branch that succeeded, its branched field will be set and the epc field will contain the target address of the jump or branch that should be directed to the PC. Thus the way the pc variable is set in the Fetch stage code is not as shown above, but instead by the more complicated: int pc = (conf4 != null && conf4.branched) ? conf.epc : PC.read();
Is this kind of code `legal'? Does it properly represent what happens in hardware? Yes, it does. The pc value here is a signal level (measured in volts) on a metal line. The Write and Fetch stages are running at the same time. All it needs is a bit of combinatorial logic to substitute on that line at that moment the value being read from the PC register in the Fetch stage by the value being written to the PC register in the Write stage. The Decode component class within the pipeline
Similarly the Decode tick() method groups together the code from the CPU1 fetch/decode/execute loop that implements the decode funtionality.
The only addition with respect to CPU1 has been the very few lines of code that move the data in the conf0 holder on entry across to the conf1 holder on exit. The stage fills out conf1 with all the broken-out fields decoded from the IR instruction (itself recorded as is in the ir field). The Read component class within the pipeline
The Read tick() method contains precisely the code from the CPU1 fetch/decode/execute cycle which reads the registers specified in the instruction, filling thereby the two-word data-holder for the stage (called r ):
All the broken-out fields from the instruction decode are present in the conf1 holder on entry to the stage, and are moved to the conf2 holder on exit from the stage. The sssss and ttttt fields are the ones which determine the registers. The Execute component class within the pipeline
The execute stage tick() method is implemented using all the code from the CPU1 fetch/decode/execute loop which was dedicated to setting up and running the ALU during an instruction.
All the broken-out fields from the instruction decode are present in the conf2 holder on entry to the stage, and are moved to the conf3 holder on exit from the stage. The func field configures the ALU behaviour. In some cases data is provided directly from other broken-out fields (such as the shift value in a logical or arithmetic shift instruction, which is provided by the hhhhh field), but usually the data provided to the ALU comes from the output holder r from the Read stage. The stage fills the 2-word holder (called s ) with the (two) subsequent outputs from the ALU. They're usually a 32-bit result and a single carry bit, but sometimes two full 32-bit words are produced, depending on the operation carried out. Multiplication is one of the latter cases. It produces a notionally 64-bit result, output as two full 32-bit words. The Write component class within the pipeline
The Write stage's tick() method does the final write-back of results to registers or memory. It collects together all the relevant code from the CPU1 fetch/decode/execute loop.
The broken-out fields from the instruction decode are present in the conf3 holder on entry to the stage, and moved to the conf4 holder on exit from the stage. These fields drive where the register unit writes to, if the register unit is involved in the write. For an arithmetic operation like ADD, the ddddd field specifies the output register.The instruction decode is then finally used one more time in its embodiment as the conf4 copy just after the Write stage finishes in debug mode in order to print out details of the completed instruction - there's no physical need for them in the CPU at that point. The author has also had to carry through in the code here in the Write stage the maintenance burden accepted when deciding to forward changes made to the PC to the Fetch stage immediately, without waiting for the next clock tick. Wherever the PC is written here (i.e., in the stanzas dealing with the jump and branch instructions), the conf3 holder is conscientiously updated with the target value in its epc field, while its branched field is set to true.
Notes on the pipeline codeAs in the unpipelined code, there are classes representing an ALU, a clock, a memory unit, a register unit, registers, and so on. If you ask for a lot of debugging output ("-d -d"), an image of the state of the pipeline will be output with each tick. Because the pipeline always fetches a new instruction as soon as the old instruction has cleared the fetch stage, it effectively is running a branch-prediction in which branches are predicted to fail, because the instruction that is (pre-)fetched into the pipeline is from PC+4. Even though the pipeline forwards changes in the PC from the Write stage to the Fetch stage immediately, that leaves in the Decode, Read and Execute stages instructions that have been prefetched while the branch was proceding towards Write but had not got there yet. Thus the pipeline needs to and does take care to flush those later instructions that have been erroniously prefetched whenever a branch instruction reaches the Write pipeline stage having succeeded at the Execution stage. Those instructions should (likely) not be executed now, so they can't safely be left in the pipeline to eventually execute and complete! The code to do this is to be found at the end of the Write tick() method:
If you want to watch chaos in action, remove that flush. Similarly the pipeline flushes all instructions which entered later whenever a jump (j, jal, jr, jalr) instruction reaches the Write stage. As discussed above, that is because the prefetched instructions already in the pipe come from what is now the wrong code area (with high probability). The code to do this is at the end of the Write stage tick() method:
The pipeline also will (naively) not allow any instruction into the Read stage (in which registers and/or memory are read) until all instructions ahead of it in the pipe have been completed. That is because some of those might be about to alter (at the Write stage of the pipeline) data that the instruction should read now at the Read stage. The earlier instructions have to be given a chance to put the data in place before the later instruction now in the Read stage tries to read it.
This is a very crude and inexact restriction (but it works!) that could do with with being refined down to a more exact analysis of exactly when there is a register data dependency between the instructions in the pipeline and when there is not. The more sophisticated emulator code in the CPU3 class discussed later remedies that situation. The CPU3 pipeline analyses the data dependency between the read and write stage instructions and only delays the read when it really does need to wait for the write ahead of it to finish first. Note that, despite the name, the Write stage also sometimes reads from memory. During a LW instruction the address to load from is computed during the Read (base register contents) stage and Execute (add displacement to address) stage, and the Write stage hooks up the output from the memory unit to the register unit input for writing. Perhaps a better name than `Write' might be `Access Memory and/or Write Register'. Results from the simulationWe are gratified to report that the pipelined simulator code executes "Hello world" slightly faster than the unpipelined code (the simulated clock is running at 1GHz):
Exercises on getting familiar with the (unoptimized) pipelined CPU2 processor model Java codeHere are some suggestions for getting to know the pipelined CPU2 code:
Optimizing performance in the pipelineThe CPU3 process model improves the Read stage in the pipelined simulator to be more liberal about letting instructions in to the remainder of the pipeline together at the same time. The result is that the pipeline runs faster:
Can you beat that with still better pipeline optimization and control? You'll find detailed suggestions below, but running the simulator with the -d option will show you many remaining pipeline stalls which you will want to work to avoid in your own manner. Stalls are visible as the absence of an instruction in a pipeline stage as can be seen at numerous points in the printout below from the CPU2 code: % java CPU/Cpu2 -d hello_mips32 ... ,-----------.-----------.-----------.-----------.-----------. |F |D |R |E |W | `-----------.-----------.-----------.-----------.-----------' Fetch 0x80030080 ,-----------.-----------.-----------.-----------.-----------. |F0x80030080|D |R |E |W | `-----------.-----------.-----------.-----------.-----------' Decode 0x80030080 Fetch 0x80030084 ,-----------.-----------.-----------.-----------.-----------. |F0x80030084|D0x80030080|R |E |W | `-----------.-----------.-----------.-----------.-----------' Read 0x80030080 Decode 0x80030084 Fetch 0x80030088 ,-----------.-----------.-----------.-----------.-----------. |F0x80030088|D0x80030084|R0x80030080|E |W | `-----------.-----------.-----------.-----------.-----------' Execute 0x80030080 ,-----------.-----------.-----------.-----------.-----------. |F0x80030088|D0x80030084|R |E0x80030080|W | `-----------.-----------.-----------.-----------.-----------' Write 0x80030080 0: 0.000000005s: 0x80030080: addiu $29, $29, -32 ,-----------.-----------.-----------.-----------.-----------. |F0x80030088|D0x80030084|R |E |W0x80030080| `-----------.-----------.-----------.-----------.-----------' Done 0x80030080 Read 0x80030084 Decode 0x80030088 Fetch 0x8003008c ,-----------.-----------.-----------.-----------.-----------. |F0x8003008c|D0x80030088|R0x80030084|E |W | `-----------.-----------.-----------.-----------.-----------' ...
A pipeline image is produced after each complete round of stage updates. The extra "Done" message (corresponding to no pipeline stage) is emitted as an instruction leaves the pipeline. It will eventually be where a check for interrupts is performed. With a perfect pipeline design in this particular CPU, 220 instructions would take 0.000000220s to execute, and the pipeline would always be full (i.e. no stalls), resulting in one instruction completed every clock cycle (every nanosecond), i.e. 1000MIPS (1000 million instructions per second). With the pipeline more or less only half-full on average, one instruction will complete only about every 2 clock cycles, i.e. 500MIPS (500 million instructions per second). The non-pipelined CPU simulator took about 5 clock ticks to execute every instruction. That's 200MIPS (200 million instructions per second). Here's the pipeline from CPU3 executing the same instructions as shown for CPU2 above: % java CPU/Cpu3 -d hello_mips32 ... ,-----------.-----------.-----------.-----------.-----------. | F| D| R| E| W| `-----------'-----------'-----------'-----------'-----------' Fetch 0x80030080 ,-----------.-----------.-----------.-----------.-----------. |0x80030080F| D| R| E| W| `-----------'-----------'-----------'-----------'-----------' Decode 0x80030080 Fetch 0x80030084 ,-----------.-----------.-----------.-----------.-----------. |0x80030084F|0x80030080D| R| E| W| `-----------'-----------'-----------'-----------'-----------' Read 0x80030080 Decode 0x80030084 Fetch 0x80030088 ,-----------.-----------.-----------.-----------.-----------. |0x80030088F|0x80030084D|0x80030080R| E| W| `-----------'-----------'-----------'-----------'-----------' Execute 0x80030080 ,-----------.-----------.-----------.-----------.-----------. |0x8003008cF|0x80030088D|0x80030084R|0x80030080E| W| `-----------'-----------'-----------'-----------'-----------' Write 0x80030080 0: 0.000000005s: 0x80030080: addiu $29, $29, -32 Read 0x80030084 Decode 0x80030088 Fetch 0x8003008c ,-----------.-----------.-----------.-----------.-----------. |0x8003008cF|0x80030088D|0x80030084R| E|0x80030080W| `-----------'-----------'-----------'-----------'-----------' Done 0x80030080 Execute 0x80030084 Read 0x80030088 Decode 0x8003008c Fetch 0x80030090 ,-----------.-----------.-----------.-----------.-----------. |0x80030090F|0x8003008cD|0x80030088R|0x80030084E| W| `-----------'-----------'-----------'-----------'-----------' Write 0x80030084 1: 0.000000007s: 0x80030084: sw $31, 28($29) Execute 0x80030088 Read 0x8003008c Decode 0x80030090 Fetch 0x80030094 ,-----------.-----------.-----------.-----------.-----------. |0x80030094F|0x80030090D|0x8003008cR|0x80030088E|0x80030084W| `-----------'-----------'-----------'-----------'-----------' Done 0x80030084 Write 0x80030088 2: 0.000000008s: 0x80030088: sw $30, 24($29) Execute 0x8003008c Read 0x80030090 Decode 0x80030094 Fetch 0x80030098 ,-----------.-----------.-----------.-----------.-----------. |0x80030098F|0x80030094D|0x80030090R|0x8003008cE|0x80030088W| `-----------'-----------'-----------'-----------'-----------' ...
What's new?The Java source code still has exactly the same structure at top level:
Lower down in the code hierarchy, there's also no difference anywhere except in the internals of the pipeline Read stage. There are extra dependency-calculation units involved in the CPU. In fact, there are three. They calculate the set of input registers d1.ins, d3.ins, d4.ins on which the instructions respectively in the Read, Execute, Write stages depend, and the sets d1.out, d3.out, d4.out of output registers that they affect. The input to the dependency unit is the configuration information in the little data holder at the entrance to the Read stage of the pipeline. The dependency calculation unit is represented by a new Depend class in the java source code. It only has one method, which performs the required calculation.
The return type DependReturnT carries the pair "ins, out" of long integer bit masks. In the CPU pipeline, the bit mask calculation
is carried out, and if there is indeed some input register for the instruction about to enter the Read stage ("d1.ins"), which will be amongst the registers written by instructions run by the Execute or Write stages ("d3.out | d4.out") then the entry into the Read stage is postponed and the pipeline stalls. The code inserted into the pipeline managent code for the Read stage is exactly the following:
The "~1" excludes bit zero from consideration. It's the bit representing a dependency on the $0 register, which is always zero no matter what. It does not matter if the instruction tries to read from the $0 register while another instruction ahead of it in the pipeline has yet to write to $0 because the register will not change. The code has stuck to a high ethical standard by using three different dependency units in order to do the three calculations involved more or less simultaneously, thus "emulating" what the hardware would do inside a single clock cycle. Reusing just one dependency unit to do the three in the hardware would require complicated circuitry and a special three-times clock multiplier inside the unit, and it really would not be feasible. Exercises to get familiar with the optimized pipelined processor modelYou'll find some meaty exercises here. The idea is to improve the pipeline further so that the runtime figures for hello world get better. Read the "Performance" chapters of Tannenbaum and of Stallings for more ideas. Implementing a branch delay slotHere's a radical idea: don't flush the following instruction in the pipeline after a jump or successful branch! If you look at the assembler code generated for the Hello world program, you will see that most every jump and branch instruction is followed by a no-op. This position is called the `branch delay slot'. Many real MIPS architectures do not flush the pipeline after a jump or a branch has rendered inappropriate the prefetched instructions following on behind. That is because it would stall the pipeline (evidently!), and since branches and jumps are common (30% of a real code load), the pipeline would perform badly on average. Instead, the architecture lets the pipeline drain naturally for one instruction more, and relies on the compiler to make sure that that `delay slot' behind the jump or branch contains something inoffensive or even useful if executed. It is common, for example, for a compiler to put the stack shift that precedes a subroutine return in the delay slot. It gets executed after the jump exits the subroutine on such an architecture. It will be executed just before the calling code resumes. While the machine code for Hello world has not been generated specifically for that context, the compiler has carefully avoided placing in the delay slots anything that might be harmful, just in case it does get executed (in some hypothetical universe). So there is no harm in executing it, and there is just a chance that the speed might possibly improve overall. It is not going to be a loss. We were going to "waste" the one cycle the no-op takes in starting refilling the pipeline. We might as well execute a no-op at the same time. But the real speed-up, if any, is going to come when we do a JAL to a subroutine and we execute the instruction in the delay-slot that should notionally follow the return from the subroutine before arriving in the subroutine. The compiler will have ensured that the shuffle is semantically harmless, and it might be helpful. If the compiler knows its socks, it will be helpful. The result from that instruction will be available way ahead of time, which might prevent the instruction after it from stalling waiting on the result. It is hard to imagine how getting the result you want way ahead of time could slow things down. Perhaps when the result occupies a register that could otherwise be used by the compiler to avoid storing an intermediate in memory. But MIPS has plenty of registers, so the compiler is not likely to be tight for those. It is simple to "not" do something. Just drop the code that does it: At the end of the pipeline code, inside the do_write_tick method, you will find the comment "jump completions need us to abort anything else pipelined behind ...", and similarly for branch. The comment precedes the business end of a flush: conf2 = null; conf1 = null; conf0 = null; which wipes out the instructions within each of the instruction holders on the entries to the stages following behind. You just have to not set to null the first of those (conf2, conf1, conf0, in that order) which is not already null. That is the delay slot instruction. It is alright to continue to null the rest - indeed, you must. However, that's not quite the end of it. For a JAL and JALR instruction, the following JR no longer should return from the subroutine to the current PC+4 (the next instruction), but to PC+8 (the next but one instruction - the next instruction is the one in the delay slot and it already got executed after the jump itself and before the first instruction in the subroutine). So JAL and JALR have to load the RA register not with PC+4, but with PC+8. That's in the Write stage. You need to look very carefully indeed at the way JALR and JAL pass through the Write stage and arrange by hook or by crook that that load to RA happens the new way, with PC+8 instead of PC+4. JALR is an opcode 0 instruction, so it is dealt with in the stanza in the Write stage that deals with the register instructions. There is an opportunity to alter what happens with JALR before the write to the register unit in the stanza, and also an opportunity after. I would probably choose to add an intercept "before", where there is already a s.c=conf.pc insert for JALR. That can be changed to s.c=conf.pc+4. The s.c value is written to the target register for the instruction, which in the case of JALR is RA. The conf.pc value is the PC value for the next instruction after the jump. JAL is simpler to figure out, since it and J get their own dedicated little stanza in the Write stage code and it is easy to see what happens for JAL and change it just slightly from an RA.write(conf.pc) to a RA.write(conf.pc+4). For extra kudos, do the "+4" using an extra specially dedicated ALU. That's how hardware does arithmetic. If you don't manage the JAL and JALR modification for the jump return, don't worry too much: the delay slot instruction is just going to be executed twice each time :-). Once after the jump to the subroutine and once on the return from the subroutine. That's likely not harmful, especially as it's often a no-op. When it's not a no-op, well, then, yes, it could be harmful. Sometimes it's a LUI or other instruction that can be executed twice harmlessly. Sometimes it's not. You could probably ride your luck and get a sensible execution out of it all. But executing instructions twice will certainly ruin your execution timings. A truly amusing side-effect of this change is that each subroutine as it ends (with a JR back to the caller) accidentally executes the first instruction of the subroutine following it in the memory map. The compiler has taken care in constructing the layout to make sure the accident is harmless! Watch the execution trace to spot the extra instructions and see how the effect of each such 'little accident' is naturally nullified by an instruction following soon after. Why hasn't the compiler just padded every subroutine with an extra few no-ops before the front? Probably because making subroutines further apart would negatively affect the program cache. Changing the default prefetch prediction mechanismHere's a hint as to how to" improve" the pipeline prefetch mechanism. Note that this will not natively mix well with the previous hint on how to arrange to always execute the `delay slot' instructions, and so I'll finish up with extra instructions on how to do both at once. The defaukt prefetch always brings in the instruction at PC+4 as a best guess for what comes next. The relevant code is in the Fetch stage. There it reads the PC register with pc=PC.read() modifies the value by adding four, fills the IR with IR.write(memory.read32be(pc)) as the prefetch guess, and sets the PC with PC.write(pc) To change the default prefetch guess, all you need to alter is the "modifies ... by adding four". If a straight jump (J or JAL) instruction is just ahead in the pipeline, in the Decode stage, then you know that it is going to set the PC if it ever gets to the Write stage, so why not guess that it will and set the PC the way the jump wants now? If we're wrong, then the jump will be preempted by some other branch instruction reaching the Write stage first and flushing the whole pipeline clean anyway, so there is not a lot to lose. So change the Fetch stage to check the instruction in the conf1 holder that should contain the instruction that is exiting the Decode stage (the way the pipeline is executed in the simulation, the stages ahead 'go first'). The fields should be filled out. If conf1.op is J or JAL then there is work to do. The jjjjjj...jjjjj field of conf1 should by then contain the jump target address (but check .. see how the jjjjjj...jjjj field is used to generate the address in the Write stage code), so set pc=conf1.jjjjj...jjjjj instead of "adding four". Now in the do_write_tick code you have to sometimes suppress the blind pipeline flush that follows a J or JAL instruction. As in the delay slot hint, use the comment "jump completions need us to abort anything else pipelined behind ...", to locate the business end of the flush: conf2 = null; conf1 = null; conf0 = null; Ensure that you have the code that triggers on jump and not branch. If necessary, separate the conditional if into two stanzas, one for jumps and one for branches. In the/a stanza for a J or JAL instruction you have to check the immediately following instruction's address by looking for the first non-null value among conf2, conf1, conf0, and reading the conf.pc field from it. If it is 4 more than the address of the jump instruction target, it is right, and one should not flush the pipeline. If it is not right, then the flush should proceed as usual. I'm told by people who've done it that if you get the prefetch guess perfect each time for a J and JAL then you don't ever have to check for whether to flush behind a J and JAL or not, just rely on it and never flush. That's all. Of course, you can improve this to take account of JR and JALR instructions too. If there is one of those ahead in the Read stage (and nothing between Read and Fetch stages that might also change the PC), then the register containing the address they will jump to has been read (into the r.a field, I believe, but check!) and you can fish out the address value and set the PC from that in the Fetch stage, just as you have already done for J and JAL. Remember to also extend the suppress of the blind pipeline flush in do_write_tick. Why stop there? Aren't branch instructions ahead also fair game for this play? By the time they are exiting the Exec stage it is known if they will branch or not. But the branch target address itself is not known until they exit the Write stage, which is a bit late. By then the branch instructions themselves would be changing the PC, so it's hardly "guessing" to have the Fetch stage do it on its own account. If you ask me, one could move the calculation of the branch target address backwards into the Exec stage. Sure, one could continue to write the PC from it only in the Write stage, but the target address could be readied in the Exec stage. Now the branch is fair game for the prefetch to use as an early cue. If there is one ahead in the Exec stage (and nothing between Exec and Fetch that might also change the PC) then if the branch is successful (the s.z field is set in the Exec stage) you can use the calculated branch target address to set the PC in the Fetch stage. Remember to extend the suppression of the blind pipeline flush in the do_write_tick code to cover this case too. If you wanted to improve on even that, you would guess in Fetch which way the branch ahead were going to hop while it was still in the Read or even Decode stage, using a little cache that records which way the branches have jumped in the past. I used a 16-entry 1-way cache when I tried this. The cache records for each of the last 16 branch addresses that have been seen the address of the eventual branch target (PC+4 in the case when the branch fails). The information in the `branch cache' is brought up to date whenever a branch exits the Write stage. You can use that same cache to also `remember' where JR and JALR instructions jumped to last time, and use that to guess where they will jump to again while they are still in the Decode stage (they only figure out for sure where they are going in the Read stage, when they actually read the register). Guess right and you avoid one `erronious' instruction following on behind the JR or JALR being flushed when the jump eventually gets around to happening in the Write stage. Guess wrong, and you lose nothing. It's quite tricky doing all of this without getting into a mess, but the J and JAL intercepts I suggested to start with are easy. Taking it along further from there requires excellent programming skills and close control of all the interactions that develop, so go easy, test after every single change, plan your changes to be testable as you go, line by line (old programming maxim: the universe bites, don't give it a chance to), and be ready to back out one of your planned changes like a shot as soon as it goes wrong, as it will. Second or third time at it you may get it right. First time at it is always just for practice. If you are going to mix doing this with allowing execution of the delay slot instructions (previous hint), good luck, and please realise that you will always have to let jump and branch instructions 'escape' at least as far as the Read stage before cueing off them for the prefetch, as suggested above. Only J and JAL instructions are affected by this consideration. You want the standard prefetch +4 mechanism to be still at work to drag one more instruction in behind them (the `delay slot' instruction) in the usual way while they are still in the Decode stage. So start watching for J and JAL in the Read stage, not the Decode stage. And modify the suppression of the blind flush in the do_write_tick code so that it checks the address of the second following instruction, not the first following. You really need to skip and spare that delay slot instruction! Other ExercisesEssentially, you want to try and keep the pipeline rather fuller than it is at present.
There are no easy options! The best thing to do is catalogue the stalls that you can see ocurring, and figure out some way of filling the vacancies with work to be done. The most obvious trick is to fill with instructions promoted out of order from behind, where it's allowable, but there won't always be instructions yet in the pipeline that can safely be promoted. The only answer to that is a longer pipeline, or two pipelines, so that more instructions are visible to the CPU at any one time and therefore there are more potential candidates for promotions. You need to experiment - the worst you can do is not go any faster. I'll be happy to help with structuring your code so that it achieves its aim clearly and concisely, which is 80% of the battle! (if you can't see what your code does, then you cannot see why it doesn't do what you want it to do). Adding a memory cache to the modelTo study the effect of caching, a memory cache has been added to the model. The augmented Java is the CPU4 class code. Whereas memory accesses take 2.5ns, cache accesses take just 1ns. The new cache is 64KB, organised as 32KB of program cache, and 32KB of data cache. The two parts are both 'direct-mapped' and 'write-through', with cache lines that are 4 bytes long. That is to say that the cache always reads 4 bytes at a time from main memory, and always writes 4 bytes at a time to main memory. If the cache needs to read the byte at address 57, then it reads the bytes at addresses 56, 57, 58, 59 all at the same time, even though bytes 56, 58, 59 are not needed. Ditto for write. Saying that it is a direct-mapped cache means that there is only one possible place in the cache for each byte from main memory. In the case of a byte with address n, it goes in cache line number (n >> 2) % 8192. There are 8192 (i.e. 2 to the power of 13) cache lines in each cache, each containing 4 bytes. The byte goes in the line that has the number formed from the 13 low bits 14-2 of the byte's address. That is a fair design for a non-multitasking operating system, but the cache will thrash badly if more than one program runs alternately in the CPU. The cache line that fills with the group of 4 bytes starting at address n gets given the cache tag (n >> 2) / 8192 consisting of the 17 high bits 31-15 of the byte's address. Inside the cache, the tag of the predicted cache line is examined to determine if a wanted byte is in the cache or not. The cache is write-through, which means that as soon as data is written to the cache, it is written on to main memory too. This makes writing to the cache as slow as writing to main memory. So why bother? The answer is that one would have to write to main memory anyway, and letting the cache snoop the data on the way there doesn't cost anything extra over that. It's just that one could have run even faster if main memory could have been updated opportunistically instead (a "write-back" cache). On the plus side, it saved me effort, as I didn't have to put in the accounting for whether data in cache has gone to main memory yet or not. Direct mapping also saved programming effort in the code because no (non-trivial!) LRU algorithm was required. There's no "choosing" which cache entry to evict when a new datum is written in a direct-mapped cache. There is only one place each datum can go, so only one possible choice for eviction. What's new now?Concretely, the caching model differs from the non-caching models in terms of the Java code as follows: There is no difference visible at the top level:
There is a new Cache class representing the cache, and the only difference in the code is that the Memory unit has two Cache objects created inside it by the main() setup code. Caches have just read and write methods for 32-bit integers (4 bytes) at a time. Read can raise an exception (when the cache doesn't have the data requested), write always succeeds. When memory wants to read or write just a single byte to cache it has to diddle with the 32-bit cache data itself. Both cache read and write methods take the address/4 as argument, because they always deal in sets of 4 bytes.
The constructor builds an internal array of nlines cache line tags and a corresponding space for the lines of cache data themselves, each 4 bytes long:
A cache write involves calculating the array index of the cache line that is affected (line_idx) and checking the tag on that line to see if it matches that for the address being written (line_tag). If it does, there has been a cache hit on write. If it does not, then the write is a cache miss. The hit/miss statistics are collected for later, though the code inserts that do that are not shown here.
Cache reads throw an exception if there is a cache miss.
Again, the statistics-collecting code inserts are not shown here. Neither is some carefully engineered timing code which calculates how long the cache access would have taken. The timing code can be switched to use the timings appropriate to write-back cache for comparison purposes. Use "-o CACHE_TYPE=2". Type 1 is the (default) write-through cache. The memory unit read methods (for single bytes and 4 bytes) now ask the cache first. If the cache read throws an exception, the main memory area will be consulted directly instead, and the cache updated with what is found. Memory write methods always update both main memory and cache ("write-through") together.
The read8 and write8 methods are not shown. They pull in a whole cache line at a time and then update or isolate only the byte that is requested. MEMORY_LATENCY is 2.5ns in the code, versus a CACHE_LATENCY of 1ns. Memory reads which hit cache take only 1ns. Memory reads which miss cache take 2.5ns. Memory writes ("write through cache") always take 2.5ns. The CPU may be supposed to have its clock cycle elongated ("wait state") in a load or store in order to allow for the expected length of memory accesses. If the memory is slower than the 2.5ns allocated, it won't work!
Results from the caching modelWith the new caching model, the processor simulation runs the "Hello world" code as shown in the table below. The first row is obtained by temporarily setting all memory accesses to take 1ns via "-o MEMORY_LATENCY=1000". The label on the row reflects the idea that the speed seen is the same as what one would get if one surreptitiously pre-loaded all code and data into the cache before program start, and let the cache "write back" updates (later) rather than "write through" to main memory (immediately).
It is clear that the cache saves at least 200 main memory reads (about 500ns). It is enormously influential here. A look at the statistics produced by "-d" on the command line shows that the cache intercepts 320 of 370 program instruction read attempts: % java Cpu4 -d hello_mips32 ... 220: 0.000000739s: 0x80030014: sb $3, 0($3) ... prog cache read hits 320/370, write hits 0/0 data cache read hits 52/52, write hits 12/19 % That's interesting, because only 220 instructions in total are executed to completion in the "Hello world" program. The extra reads occur when instructions are prefetched and then flushed from the pipeline before they can complete. Evidently 150 poor predictions were made. It would be worth trying to improve the pipeline's prediction mechanism. At the moment the prefetched instruction is always the next instruction in strict address order in the code, at the PC+4 location. The count also shows that there are only 50 different instructions to execute (the program loops through them) and they all ended up in the cache. One has to conclude that caching the program text is a major win on its own. The data cache intercepted all (52) of the reads that it tried, which shows that the data was always written before being read. The "data" is actually the contents of registers saved onto the stack before subroutine calls. Yes, writing does occur before reading there. The count shows that 7 different stack locations were used overall (19 writes, of which 12 evicted data already present in the cache). That's enough data to predict the theoretical perfect performance from a pyschic pipeline. It's in the last column:
For the top row (final column), We've counted just 220ns for 220 instructions, at 1ns apiece. For the middle row (final column), We've counted the 220ns for the 220 instructions, plus an extra 1.5ns for each of the 50 reads from main memory of the program instructions that must necessarily take place, and an extra 1.5ns for each of the 19 data writes to main memory that did take place. For the bottom row (final column), We've counted the 220ns for the 220 instructions, plus an extra 1.5ns for each of the 220 reads from main memory of program instructions that must take place, and an extra 1.5ns for each of the 19 data writes to main memory that did take place. You could fill in the blanks in the table by retro-fitting the more sophisticated memory-with-cache class code into the non-pipelined simulator code. It should drop right in. Exercises with the optimized pipelined caching modelImprove the cache in the cached and optimized pipelined emulator CPU4 java class source code. It's only direct mapped write-through by default. See how good you can get the cache figures with respect to the "perfect psychic cache" noted above. Doubling cache line lengthYou may easily improve the CPU performance figures by making the cache lines longer, so that more data is read-ahead at a time into the cache, saving time overall. But don't go overboard. It's not certain that even 64-bit wide data paths from cache to main memory would be approved by the project accountant! And it's unlikely that you'll get anywhere as much improvment in doubling from 64 to 128 bits as you do in doubling from 32 to 64 bits. Here are hints on how to extend the cache lines in the CPU4 model code from 4 bytes to 8 bytes length. That should make cache hits rather more frequent. Indeed, indications from a few test runs are that it's something like a 10% win from this rather easy coding change in the model. However little more one would win with 16 byte long cache lines, it would require substantially more coding work and is not worth even thinking about until you have tackled this task first. The changes you make should be centered on the Cache.java file, which contains the cache methods read32be and write32be (plus its simpler-minded cousin, update32be), in about 20 lines of code. You will modify them to read64be and write64be methods, allowing 64-bit data to be read and written from/to cache. Start by changing the linelen=4 initialization to linelen=8, doubling the length of the cache lines in the cache and halving their number. Change the type of the read method to allow it to return a long, instead of an int. Change the declaration of the variable val that is returned from int to long, and change the way it is read from a cache line to use the utility function grab64be (write it!) instead of grab32be. Cache lines are now 64 bits long, not 32, so the change is forced. That's it for read. Similarly, change the type of the write method to allow it to accept a long, instead of an int. Change the call to put32be that puts its argument into a tag line to use put64be (write it!) instead. Cache lines are now 64 bits long, not 32, so the change is forced. Make the same changes in the update method, which is the same as write bar the extra cache statistical accounting lines that write has and update has not. That's it - you've got a couple of 64-bit cache methods. You have now notionally widened the bus between cache and memory to 64 bits. But now you're temporarily stuck, because the two calls in Memory.java are to the old cache read32be and write32be/update32be methods, which you just modified and renamed to read64be and write64be. The old 32-bit cache interface no longer exists. The bus between memory and cache is now wider than 32 bits - it's now 64 bits wide. You need to fix something here. Before thinking about it, make yourself a couple of new methods in Memory.java, called read64be and write64be. Make them by modifying the existing memory read32be and write32be methods, and change the type returned by read and the type accepted by write to long, from int. Then there'll be room to pass 64-bit data through them. Mark them as private, as there'll be no external use of these methods. Once they're made, we'll see a use for these named lumps of code - they're nothing more significant than that - as the memory's end of the memory-to-cache newly 64-bit wide bus. For read64be, change the declaration of the data variable to long, from int. And load it using a cache read64be method call, not a cache read32be method call. The address passed to the cache in the call needs to be divided by another 2 too, as the cache uses whole lines as data items and expects not to have useless zeros on the end of addresses passed to its methods (this is arguably a design mistake, and you might wish to correct it). Cache lines are twice as long as before, so there are half as many of them as before, so cache addresses are half what they were. If the cache misses, the code falls back to looking in the memory area, and the method call needs to be changed from a grab32be to a grab64be, since we are now dealing with 64 bit data. Finally, the snoop of the data brought back from memory to the cache needs to be done with a cache update64be method call, not an update32be call. And the address passed in the call needs to be divided by 2. For write64be, exactly the same sorts of changes need to be made. There are only two lines that need changing! Remember to return 8, not 4, in case of success. The write method returns the number of bytes written successfully. Now you have a couple of very neat pieces of code, write64be, read64be, in Memory.java, but no other code calls them! You just made them, fresh, and they're private to memory. The existing CPUx code calls to a public memory read32be and write32be method when it wants access to memory and hopefully those vanished when you modified them to read64be and write64be, so the compiler will complain. You have to reinvent a public read32be and write32be in Memory.java for the CPU to call to. There's still only a 32-bit bus between CPU and memory/cache and you need the interface for it! For the memory read32be method, make it call the private memory read64be method that has access to the 64-bit memory-to-cache bus and throw away `the wrong half' of the result. Notice that if you are interested in getting the 32-bit int at addr (necessarily a multiple of 4) for read32be, you have to ask for the 64-bit long at addr&0xfffffff8 (the multiple of 8 equal to or just below it) from read64be. That is, you will call long data64 = read64be(addr & ~7) 8-byte memory and cache blocks (`long's) exist at addresses that are multiples of 8 (called "8-byte aligned", or "64-bit aligned" addresses). They do not overlap. Ditto 4-byte `int' blocks and addresses which are multiples of 4, also 2-byte `short' blocks and addresses which are multiples of 2. So read64be can be expected to get 64 bits from the 64-bit-aligned memory address you supply to it and you want just 32 of those 64 returned bits. So what is the `wrong half of the result'? Here's a picture of the 64 bits at memory address 0x18, addressed byte by byte:
What if you want the 32 bits at address 0x1c? That's bytes 0x1c, 0x1d, 0x1e, 0x1f. Then you will ask read64be for the eight bytes pictured above at 0x18, and throw away the first four (the big end) and return the remainder (the little end). Here the bytes to throw away are shown in red, and those to keep are shown in green:
In other words, if addr == (addr & ~7) + 4 then you will want to return (int)data64 What if you want the 32 bits at address 0x18? That's bytes 0x18, 0x19, 0x1a, 0x1b. Then you will ask read64be for the eight bytes at 0x18, just the same, and throw away the last four (the little end) and keep the first four (the big end):
In other words, if addr == (addr & ~7) then you will want to return (int)(data64 >> 32) So you throw away either the big end or the little end of the 8-byte long returned from read64be, depending on the address of the 4-byte int you want. The `wrong half' is whatever half you have to throw away, and it varies from case to case. For write32be, never mind the wastage for now, just make it call read64be first to get 64 bits, modify 32 of those with the 32-bit data you want to write, either the big end or the little end, then write all of the modified 64-bit data back with write64be. Start with the read you've been advised to do: long data64 = read64be(addr & ~7) You want to write `int data' at addr. In the end you will use the expression data64 = (long) topbits << 32 | botbits & 0xffffffffL to create the 64-bit data to write with write64be from two 32-bit integer halves. Note that the 'L' means a 64-bit constant is understood here, and this one contains 32 zero bits in its top half and 32 ones in its bottom half. We'll look here at how to get the 32-bit integers topbits and botbits.
addr == (addr & ~7) + 4 then int topbits = (int)(data64 >> 32) is the big end of the 64-bit data read at addr & ~7, which you do not change, and int botbits = data Check the picture above to confirm. If the target integer address is addr == (addr & ~7) then int topbits = data and int botbits = (int)data64 That's the little end of the 64-bit data read at address addr & ~7, which you do not change. Again, see the picture above for confirmation. Build data64 from topbits and botbits as advised above, and write it to addr&~7 with write64be. Yes, you can improve that. It's better to look in cache first during a 32 bit write. If the data is in cache already, then there is 64 bits of it right there that can be modified in situ and only 32 changed bits need be written through to memory. No memory read is required. Only if the data is not already there in cache does an extra 32 bits need to be read from memory into cache to fill the cache line completely. The 32 bits that are being written can be written straight through to memory, as well as into cache. So the memory read during memory write suggested as an expedient above can be avoided at the cost of some complicated if-then-else-ing in the code. And then you may want to make the lines longer still. Making the cache 2-wayHere are some coding hints on making the model cache 2-way. I would go about it in a low-level fashion, doubling the number of arrays held inside the present cache object. You, however, may wish to go about it in a more "programmerly" fashion, inventing a new cache object (class) that contains two of the old cache objects, a primary and a secondary. On read, check both of these internal caches for the cache line that's requested. Just pass on whatever you receive in your read request to the two internal caches read methods in turn. One of them may have it (which means not throwing an exception in reply). If neither has it, i.e., both internal caches throw exceptions on read, then throw an exception back to the caller. On write, choose one of the internal caches to write the cache line to. If the entry at that address was already in the other internal cache, delete it from there! (Alternatively, don't write it to a different internal cache if it is already in one). That's all. Yes, your new cache has a pretty lousy replacement policy - effectively pure happenstance. You really want to improve it! Perhaps maintain a table of which of the two internal caches has the older entry for each cache index. Then when you write, choose to write to the internal cache with the older entry at that index position. Remember to change round the table entry for which is older afterward. Update the table entry on read too. That implements a LRU (`least recently used') replacement policy. You can do all that in a low-level way too, modifying the internals of the existing Cache class to include two sets of what it has inside it now, plus the extra table of `oldest' indices. I'm sure I'd do that. Expand your calls to the methods of the internal caches out into flat code, and you should get what I would have written. It's a much closer representation of the hardware. For starters, you'll have to name the two sets of internal local variables (`names of traces') differently, so you will become aware that they correspond in real life to separate parts of the chip real-estate. Making the cache 2-way or 4-way associative ought not to improve the performance figures for the single "Hello world" program, because there is no thrashing. A program larger than 32KB, or which used data sets larger than 32KB, would cause cache thrashing. So would running two different programs alternately, as is effectively the case with the CPU5 model that we will look at next. There the interrupt handler plays the part of a second program running alternately, and performance will be improved by a 2-way associative cache. Making the cache write-backYou might try making the cache write-back and check the predicted performance figures - make writes take only CACHE_LATENCY each time. How would you make the cache write-back? You'll start by taking the control of the write-through to memory out of the hands of the Memory class write method! Do it in the write method of the Cache class instead, where you can put in a call to memory.update32(addr, data). Remember to reconstruct the appropriate memory address from the address the cache receives (which is the memory address divided by 4, as I had it originally). You will have to multiply by 4. Or 8, if your cache lines are 8B long and you are dividing memory addresses by 8 when passing a line to the cache. Etc. Of course, to call the memory update method, you will need to implant a reference to the memory object in the cache. Declare a new field and fill it just after the cache is created, in the main code. In the cache write method, most of the time you do not want to fire the update-through-to-memory call. That will be the default action ("don't write through" - it's easy to implement1). Every time you do the don't, you will have to set a mark in a boolean table of dirty cache lines instead. That table will show which cache lines are pending on a write through to memory. I'd simply declare a boolean[] dirty array the same size as the number of cache lines, and not try for anything fancier. If the cache write method tries to overwrite a cache line that is marked as dirty in the table with a different cache line, then and only then you have to use the memory update call to write through the old cache line to memory immediately. The new line is dirty too (since it has not yet been written through to memory), so the dirty annotation stays the way it is. When does this cache ever get cleaner? When it spontaneously writes a line through to memory on its own account, that's when. After that you can mark that cache line as clean in the dirty table. Every tick of the pipeline clock you want to look at the instructions that are in the pipeline (I'm talking about the Pipe.tick method code here) and see if none of them are load instructions. You'll have to examine the conf1, ..., conf4 holders op fields to determine that. If the coast is indeed clear then you can put in a call to a new cache flush method at the front of the pipeline tick code. You know that you now have 5ns in which no load instruction will be executed, and you can manage a good two memory writes in that time if pushed. The new cache flush method should simply select one dirty cache line (if each line can be written in one memory write operation, as I had it originally; if not, think again!) and update it through to memory, marking the line as clean afterwards. We know that there would be time to get this done, so call Clock.reset after the cache.flush call you've put in at the front of the pipeline tick. The cache is notionally feeding the data through to memory asynchronously in the background, so it doesn't count as time taken during a pipeline clock tick. We're simply triggering the cache flush from there and the cache is doing it while the pipeline ticks on. What about timing? With luck and crossed fingers, setting the CACHE_TYPE to 2 in the Globals class should already get the timing right for a writeback cache. But check by eye on the standard printout from each instruction's execution that load instructions are now taking less time than they used to. If it doesn't happen, let me know and we'll figure out why. Adding an IRQ handler to the caching, pipelined modelWe've added an extra final stage to the pipeline in which a check is made for interrupts and other kinds of exceptions. That's the CPU5 model. The design rationale is explained in detail below, but for the moment just note that an interrupt causes existing instructions to be flushed from the pipeline and a jump to a handler at address 0x4 to occur instead. The Cpu5 Java code evokes this model. The interface is syntactically the same as for all the other CPUs, but there are a few semantic differences which will be enumerated below:
We have created some peripherals which will run simultaneously in a different Java thread, talking across to the CPU in an unpredictable manner (from the CPU's point of view!). The peripherals we've prepared are a screen and a keyboard unit. They engage in IRQ-mediated communications with the CPU. I've embedded one screen and one keyboard together in a new console object instantiating a new Console5 class. The main code in Cpu5 now takes care to embed one of the new-style consoles instead of an old-style console in the memory unit's address intercept table: cpu.memory.console = console = new Console5(cpu); Separate threads of computation corresponding to the screen and keyboard are launched:
and from then on its up to the correctness of the simulation of the IRQ-driven I/O to keep things running smoothly. What else is new?The IRQ-enabled emulator's Java code is to be found in the CPU5 class, which runs the basic fetch decode execute pipeline. At the interface level, there is no change:
There are internal changes, however. In particular, interrupts are initiated by a peripheral setting a new IRQ boolean in the CPU's I/O bus. There's a precise protocol involved which we'll describe in further detail below. And when an interrupt handler code finishes it will run the new MIPS 'rfe' instruction ("return from exception"), and that will finish off the CPU's interrupt acknowledgment part in the protocol. So there is a new instruction to be handled. In summary, the IRQ-enabled simulator's Java code differs in the following ways from its predecessors:
STATUS, CAUSE, EPC are registers $12, $13, $14 respectively in the interrupt coprocessor (0) register index space. You can use the abbreviations $status, $cause, $epc, respectively. The mfc0 and mtc0 instructions respectively read from and write to the new STATUS, CAUSE and EPC registers (to/from the standard registers $0-$31), and that's how the MIPS programmer checks and changes them. For example, "mfc0 $1, $status" reads from the STATUS register to general register $1. "mtc0 $status, $1" moves data the other way.
We'll often put code dealing with the IRQ and IACK booleans directly in-line here, for easy reading. If you look at the real implementation, you'll find that code all duly encapsulated within methods of the IOBus class instead.
Peripheral devices using these I/O bus methods will be held up until "the coast is clear". The IRQ boolean cannot be set by a peripheral until it has first been unset, for example. A peripheral device wanting to raise IRQ via the raiseIRQ method will be forced to wait if IRQ is already set until both it and IACK become unset first. Then there is a further wait until the CPU sets IACK, indicating that it has seen IRQ and is running or going to run the handler. This semantics corresponds to the way the hardware built into I/O peripherals works.
Note the guard which checks bit 1 (using bitmask 0x2 which is ...0010 in binary and has bit 1 set and all other bits unset) of the STATUS register is set before starting to handle the IRQ. When bit 1 of the STATUS register is not set, we say that interrupts are masked. They will not be serviced. And note that it is also required that the IACK flag not be set for the handler to be started. If it were set it would indicate that the CPU were already running the handler for an IRQ, and one does not want to interrupt an interrupt (it can be and is safely done, using interrupt priorities, in other architectures).
STATUS.write(status << 16); // save status mask and zero current mask
PC.write(0x4); // prepare jump to Ox4 conf0 = null; // flush pipeline conf1 = null; conf2 = null; conf3 = null; The next cycle the CPU will naturally fetch the first word of the handler code into the pipeline and execution of the handler will commence. However, it is not that simple to copy the PC value for safekeeping because the PC may have been pre-incremented for Fetch several times after the "current" instruction was started. More details of how it is done will be found below. It's quite a little saga to figure out what it should be and you may like to consider if one perhaps needs some dedicated extra decode hardware to do it. I don't think so, but I may be mistaken in my by-eyeball evaluation. When the interrupt handler code finishes, it executes rfe, which restores PC from EPC and shifts the STATUS register down again, thereby restoring its original state. The rfe instruction is pipelined as follows:
and rfe needs no other handling in the pipeline beyond a flush that must follow on its writing the PC - the prefetched instructions trailing it in the pipeline are likely just random nonsense tagging on beyond the end of the handler code in memory, and they need to be purged:
In case rfe had to set a flag to drop IACK later rather than being able to drop it at once (because IRQ is still set high by the peripheral when the handler finishes - the CPU is generally much, much faster than any peripheral), there is an extra check just at the end of each and every cycle. It checks to see if IACK should be dropped now because IRQ has finally dropped:
Until both IRQ and IACK have dropped no new IRQ will be issued by any peripheral.
As was commented at the start of this section, that is accomplished by introducing an extra, final, pipeline stage called Irq. The stage checks for IRQ having been raised by some peripheral, performing the actions described in the paragraphs above. Entry of an instruction into the Irq processing final stage is guarded by a check of the IRQ value to see if it is even plausible that an IRQ might need processing now, otherwise the stage is skipped:
Why only check for IRQs after some instruction has exited the Write stage? And what does the CPU need to do that is based on the instruction rather than being completely generic? Why look at the instruction at all? Firstly, the CPU cannot attend to an interrupt while the pipeline contains only partially completed instructions. If we were to try that we'd find that we really wouldn't know what program address to return to with the rfe instruction, because it's not yet certain which if any of the jumps or branches in the pipeline at the time of the interrupt will be executed or not. Worse, the value of the PC when the interrupt occurs is that corresponding to the instruction being pre-fetched into the pipeline, which is not the same as the next instruction that has yet to complete. It's just not going to work. You may wish to do a cleverer analysis than I, but I've settled for not handling an IRQ at all until some instruction has just completed for sure, so we know what the next instruction is going to be. And what is it going to be? It depends on the instruction just completed! That instruction needs to be examined, and that's why there is a final Irq stage. It is precisely to look at the just-completed instruction and set up the value of the PC to be saved according to what it is. If the just-completed instruction is a jump (or rfe itself), then the next instruction has to be from the value of PC just set by the jump (or rfe) in the Write stage. Likewise if the completed instruction is a branch that succeeded. In all other cases the next instruction should be the instruction that comes 4 bytes after the address of the one that just completed. Here's the code that sets the EPC in the Irq stage. It performs the instruction-based analysis detailed just above:
The notifyAll is the mechanism used to tell all interested peripherals running in other threads (in the simulation!) that the IACK flag has just changed. Look in the Java lang API documntation to see how it and wait work.
With the pipeline flushed, the PC set to the handler address, EPC containing the return address, STATUS shifted up 16 bits to blank the current mask, IACK set, the next CPU cycle will start with the fetch of the first word of the handler code into the now empty pipeline. It's hard to see what one could do to assuage the pain of the pipeline flush, because any instruction may be followed by an IRQ handler sequence without warning, so one can't prefetch the forthcoming handler sequence into the pipeline at the Fetch stage. Can you find any ideas out there on the Web? All that occurs to me is to let the pipeline drain naturally before starting the handler. Or start the handler at the next jump or branch instruction, since the pipeline would have been flushed there too.
!IRQ !IACK; IRQ !IACK; IRQ IACK; !IRQ IACK; !IRQ !ACK The second transition marks the handler start. The handler finishes on the final transition. The CPU will not start handling another interrupt while the handler is running. It will not handle another interrupt until the sequence of states comes back to the start again. Putting it another way, the cycle of events on the IRQ line is always:
The cycle starts from the situation in which IRQ and IACK are unset, and terminates with them unset again. Note that the peripheral controls the IRQ setting and the CPU controls the IACK setting. The peripheral device must not deassert IRQ before it has seen the processor raise IACK (or else the interrupt may be missed by the CPU). The CPU must not drop IACK before it has seen the peripheral drop IRQ, even if the handler has finished (or else the acknowledgment may be missed by the peripheral). The peripheral must not raise IRQ again until it has seen the processor drop IACK (or else the CPU may see it as continuing to assert the last interrupt and thus miss the new one). PeripheralsWhat do peripherals do and how do they work with the IRQ model protocol introduced above? Peripherals are like small dumb CPUs in at least one way: they run a continuous cycle, like a CPU. But it's one in which they "do their own thing" and also occasionally try and tell the CPU about it by raising an IRQ. The IRQ means "you (the CPU) can learn something by looking here now". A screenConsider first a screen I/O peripheral. We've written it as a Screen class which implements the Runnable interface so it can be launched as a separate thread in Java. That means that it has a "main" routine called run:
The run method contains the screen's working cycle. It's a loop that only stops when the CPU stops the clock. Until then it does nothing but wait on an event from the CPU clock, likely a clock tick forward, but possibly also a notification from the CPU on a change of value in the CPU's IACK variable or its STATUS register. When the notification reaches it, it runs its private output method, which may move either 0 or 1 characters out of its internal buffer and onto the screen's physical display area:
Characters are accumulated in the screen's internal buffer as code executing in the CPU writes to a specific memory address PUTCHAR_ADDRESS and that eventually translates to a call to the screen's print method via the CPU's iobus. The screen's internal (circular) buffer is some 128 bytes in length. It is implemented via an index front that points to the front of the buffer, which is the first character due to be printed next, and an integer count that says how many characters there are in the buffer beyond front waiting to be printed. Thus the last character in the buffer is the (front + count - 1) % 128 th, counting from 0. The first character in the buffer is the front % 128 th. That modular arithmetic calculation for the index position is what circularity means! The 128th character is also the 0th character in the buffer. Here's a picture:
If one kept adding to the end of the buffer without cease (and the buffer were to accept that) one would eventually overrun the front of the buffer again, like a snake catching up with its own tail. Characters are taken from the front of the buffer by the screen hardware and sent to the physical display. Each character printed increments front and decrements count, internally. Any character sent to the screen for printing gets added at the end of the buffer, in the (front + count) % 128 th position. Each character added to the buffer increments count. The screen object also contains an integer pend which counts the number of characters it has printed from its buffer but has not yet told the CPU that it has printed, via IRQ. Every time a character is printed to the physical display, pend is incremented. Every time an IRQ is raised, pend is set to zero again. In all usual circumstances, the value will be 0 or 1 for pend. There is also an integer count tot for the number of IRQs the screen has sent out but not yet received an IACK in return for. Each time the screen sets IRQ it increments tot. Each time the screen receives IACK, it decrements tot. Again, in all usual circumstances the value of tot will be 0 or 1. And finally there is a count of the number of characters discarded since the last IRQ because the buffer was already full when they were added. It is the instance variable discard. You might like to consider a slightly different version of the screen printer, one which never suffers from the full buffer problem (incrementing discard every time that happens), but which instead simply silently overwrites the oldest unprinted character still in the buffer when it has to. I'm not sure how relatively pleasant or unpleasant that would be for someone programming for the revised screen hardware. See below. Programming for the screenThe plan is that the console object to which the memory unit redirects those single byte writes which are addressed to PUTCHAR_ADDRESS should call the screen's print method. This corresponds to a physically wired connection in the hardware. The screen's print method will place the character on its buffer, if there is room, incrementing count. If there is no room in the buffer, it will discard it, incrementing discard. Some time afterwards, the screen may issue an IRQ. The IRQ usually will signify "I have printed it", but detail can be obtained by interrogating the screen from the interrupt handler. Blow-by-blow data on what has happened is available for inspection via the control port(s). If the character was printed, pend will have been incremented (and count decremented again back down to its previous level). If the screen is still waiting to print it, count will have been incremented and pend not. If the character did not even make it into the buffer, the discard count alone will have been incremented. The wise and conservative programmer should plan on writing program code which sends a single character to the console, then waits (possibly doing something else useful if the programmer is kind to the sensibilities of the person sitting at the keyboard) for an IRQ in response. The handler should then check with the console control port(s) to see that the character has been printed. Then the programmer should arrange that the code sends another character. If not printed, the wait should be continued or the character should be resent according to circumstances. And so on. A more foolhardy and adventurous programmer may choose to send more than one character blind. So long as the programmer arranges that not more than 128 characters are sent before an IRQ has been received, and carefully counts the number of characters reported received and those reported printed in the IRQ handler code and balances that against the characters sent so that no more than 128 are outstanding at any time, everything should work fine. But it's quite a delicate piece of programming. I would be the conservative programmer! There's a real danger that we might be sending too fast for the screen to notice because of the greatly different clock rates between the two pieces of equipment, and what do we do if we see from the totals that some have been missed? Which ones are they? The totally incautious programmer will send characters without attempting to control the flow at all according to the data received during IRQs, and in consequence many characters will arrive at a filled buffer and be discarded by the screen before ever being printed, resulting in documents which look lk thi ne. This last option is effectively what we have programmed for you as a base standard for the handler. Tough luck. See below. Screen internalsHere's the implementation of the screen's print method. It's not where the difficulty lies. It just fills in to the buffer as best it is able:
The tricky code is the screen's private output method. This method runs continuously in parallel in the screen's own independent Java thread in this simulation, and reflects what happens inside the chunk of machinery that is a console on your desk. If the screen thread has some characters in the internal buffer ("count > 0") it prints the character at the front of the buffer to the display. That's visible at the start of the routine:
If there are now (or were already) characters printed to the display and unsignalled to the CPU via an IRQ ("pend > 0"), then the routine tries to issue an IRQ. Ditto if a character has been dropped ("discard > 0"). Something interesting has happened and the CPU needs to be told. The screen may now be held up trying to raise IRQ until no other peripheral has control of the IRQ line. When eventually the screen gets control of the line and does raise IRQ, then it waits for the CPU to acknowledge by raising IACK. Then it lowers IRQ since it is sure the CPU hs seen it. It waits around until the CPU has lowered IACK to reset pend, discard, etc., because the IRQ handler is notionally reading them until it finishes which is signalled by the CPU lowering IACK. What happens in summary is
So each character sent via the CPU to the screen like this generates its own IRQ. The screen data is quiescent while the CPU checks it after getting the IRQ. There are things wrong with this screen design. For one thing, the screen data is not merely quiescent but the screen itself is totally paralyzed while the CPU's handler runs! I'll ask you to help develop better designs or to strengthen this design so that it always works well, whatever the context. It could continue printing while being interrogated by the CPU (it needs to snapshot its state and present it to the CPU as a stable historical image while being interrogated and the real state can continue developing meanwhile). Running the screenThe screen works. You can test it out like this:
Running without the "-q" flag reveals the episodes in which the (simplistic, do-nothing) handler code in handler_mips32 (see below) is being executed:
There was a large hiatus of about 16 clock cycles as the pipeline was flushed and before the first handler code instruction at address 0x4 completed. 5 clock cycles of that would be the time taken for the fetch, decode, etc. of the instruction, but there is still a large pause to be explained! I expect it is the program cache thrashing. The address ranges of the program and the interrupt handler overlap modulo 32768, which is the size of the program cache. Indeed, the final lines of debug output from "-d" show considerably degraded program cache performance:
The figures for CPU4 and earlier model CPUs show 320/370 hits. Now only 6 more instructions are being read successfully first time from cache and 128 more instructions are having to be fished for in memory because they are not in the cache at the time they are needed. We have only introduced 4 new instructions by way of the handler code, 3 of which are nops. Undoubtedly the cache is thrashing. Try moving the program's virtual address placement! The rfe causes another pipeline flush, and this time 17 clock cycles are lost before the first "ordinary" code instruction completes. Some of that is perhaps simulation fluff, but it can still be recognized that IRQ handling causes significant pipeline stalls to occur, and it's good from the CPU's point of view that IRQs are relatively infrequent, peripherals being so much slower than the CPU as a rule. Interrupt Handler codeFor the tests we've prepared the interrupt handler code that does almost nothing at all - it contains just the single MIPS assembler instruction 'rfe' ("return from exception") - and the simulator loads it at the 0x4 memory address where interrupt handler code is expected to be found. The handler code is compiled via
and the handler_mips32.s file contains the single-instruction assembler code for 'rfe':
resulting in a handler_mips32 file which disassembles as follows: 00000004 (_ftext): 4: 00000000 nop 8: 00000000 nop c: 00000000 nop 00000010 (handler): 10: 42000010 rfe There are three no-ops preceding the single rfe instruction in the code that will eventually be loaded at address 0x4. More sophisticated IRQ handlers should do more, such as checking first which peripheral caused the IRQ being handled! Improving the screenThere are two aspects to improving the screen:
A better IRQ handler should check which peripheral squawked via dedicated "hardware" connections to all peripherals. That's one basis for suggesting that the hardware needs improving. According to the protocol followed, only one peripheral can send an IRQ at a time and the CPU will maintain IACK while the handler is running, thus keeping other perpherals from sending IRQ, so there is in principle no danger of confusion about which peripheral has sent IRQ while the handler is running. But how to find it out? The handler code has to use only legitimate MIPS instructions. Its interrogations of peripherals for "who squawked" must be done via memory address accesses. Conclusion: the CPU's memory unit has to be reprogrammed to map more addresses to peripheral control ports. In particular, the memory unit needs to hook up at least one address to the screen's signalled method and hence its tot variable, which indicates when this screen was the one which sent the IRQ that has not yet been acknowledged. The handler should interrogate the screen tot variable via the control port. A positive return signals "yes, it's me who signalled IRQ". The handler should use another mapping to access the screen's printed method and pend variable in order to determine how many characters have been printed since the last IRQ. The ports for these mappings need to be set up. As a simplification, a good suggestion is that reading from a single control port should return a 32-bit number composed of 5 bits each from the screen's tot, pend, count, etc. instance variables.
A keyboardThe IRQ-driven model also contains a Keyboard class. An IRQ-driven keyboard is inserted into the console component. Like the Screen component, the Java code implements the Runnable interface so it can be launched as a separate thread. We've really only sketched out the code, and it should not be considered complete as it is. You want to test and perfect it.
The keyboard object runs a continuous cycle reading characters typed on the console into an internal buffer. The passage of time in the system clock causes the code to check the console for more typed characters:
The private input method reads 0 or 1 characters at a time into the internal keyboard buffer. The detail of the code is entirely comparable with the printer output method, down to the instance variables.
The external functionality is provided by the available and read methods, which work just like System.in.available and System.in.read respectively. The read method reads off the front of the input buffer into an array supplied by the programmer:
The console unit accesses the keyboard read method for single-byte reads. The program code need only read from the memory mapping for the console keyboard data to receive a character from the input buffer, or 0 if there was none. A prior IRQ from the keyboard will have made available precise information to the IRQ handler about how many characters have been supplied and are available for reading, how many have been dropped, etc. It is the programmer's responsibility to write handler code which maintains the proper accounting. The IRQ handler will fill a program buffer and the program code will later interrogate that buffer. But I've been very lax and supplied an IRQ handler that does none of anything like that. Still, so long as the keyboard cannot supply characters with a code of 0 and you don't type too fast, polling the keyboard data port works fine with the keyboard and handler I've supplied as a rough-and-ready mostly-works way of discovering input characters! Please feel completely free to experiment and tear down and replace any of my ramshackle construction. You'll find much more sophisticated peripheral designs than mine on the Web and in your course books. I particularly think that the first part of the keyboard's input method code, reading from System.input, should be in a separate thread so it can't be blocked waiting on the CPU's acknowledgment via IACK. Not that any human is likely to be able to type faster than a CPU runs, but still ... Exercises with the IRQ-enabled modelHere are some suggestions for getting to know the IRQ-enabled CPU5 processor model.
A perfectly ordinary MIPS CPUThe CPU6 model introduces a feature of the MIPS architecture that was used as an optimization in the very first R3000 to be built - the `jump delay slot' feature, discussed as an exercise in section 3. Although introduced as a cheap optimization in the original hardware, compiler-writers took advantage of it and it became the norm for compilers to produce machine code that depended on the feature for the correct working of the program, rather than merely enabling it to work faster if the hardware possessed the feature. That led in turn to the feature becoming fossilized in the MIPS hardware designs, in order to keep older programs working, even when better optimizations became available. SPARC, PA-RISC, ... they're all RISC chip designs, and they all also (still) implement the branch or jump delay slot feature. The `jump delay slot' optimization is to always execute the instruction after a jump or branch. Thus beqz t1,+4 // skip next instruction if t1=0 addi a1,a1,1 // add 1 to a1 always increments the a1 register, no matter whether the branch is taken or not. The instruction (in this case addi) after the branch or jump is said to be the `branch delay slot instruction', or to be `in the branch delay slot'. Usually the compiler sets the instruction to be a no-op, to avoid accidents, but occasionally it finds a useful instruction to put in the slot, one that has to be executed down both branches of the conditional but which cannot be executed before the branch test. In the following code snippet, for example ... bne a1,a2,FOO // if a1 != a2 goto FOO move a2,a1 // a2 = a1 It is the case that "a2 = a1" is still executed before arriving at the target of the branch. Thus on arriving at FOO, a2 is equal to a1 although the a1 != a2 test succeeded in order to get there, and there are no intervening instructions in the program. A miracle! The exercise with CPU3 describes the benefits of a jump and branch delay slot like this: Many real MIPS architectures do not flush the pipeline after a jump or a branch has rendered inappropriate the prefetched instructions following on behind. That is because it would stall the pipeline (evidently!), and since branches and jumps are common (30% of a real code load), the pipeline would perform badly on average. Instead, the architecture lets the pipeline drain naturally for one instruction more, and relies on the compiler to make sure that that `delay slot' behind the jump or branch contains something inoffensive or even useful if executed. It is common, for example, for a compiler to put the stack shift that precedes a subroutine return in the (jump) delay slot. It gets executed after the jump exits the subroutine on such an architecture. It will be executed just before the calling code resumes. While the machine code for Hello world has not been generated specifically for that context, the compiler has carefully avoided placing in the delay slots anything that might be harmful, just in case it does get executed (in some hypothetical universe). So there is no harm in executing it, and there is just a chance that the speed might possibly improve overall. It is not going to be a loss. We were going to "waste" the one cycle the no-op takes in starting refilling the pipeline. We might as well execute a no-op at the same time. But the real speed-up, if any, is going to come when we do a JAL to a subroutine and we execute the instruction in the delay-slot that should notionally follow the return from the subroutine before arriving in the subroutine. The compiler will have ensured that the shuffle is semantically harmless, and it might be helpful. If the compiler knows its socks, it will be helpful. The result from that instruction will be available way ahead of time, which might prevent the instruction after it from stalling waiting on the result. It is hard to imagine how getting the result you want way ahead of time could slow things down. Perhaps when the result occupies a register that could otherwise be used by the compiler to avoid storing an intermediate in memory. But MIPS has plenty of registers, so the compiler is not likely to be tight for those. The CPU6 architecture implements the jump and branch delay slot as described in the exercise with CPU3 but in the more complex context of the CPU5 architecture, which has an additional interrupt handling mechanism with respect to CPU3. Care has to be taken when the interrupt follows a branch not to forget to run the branch delay slot instruction! We want the delay slot instruction following a jump or branch to be executed, and it won't be if the branch or jump is followed by an interrupt, which will naturally just flush it away. Here's the extremely ruthless code in CPU5's IRQ pipeline stage that did just that:
So .., the design expedient we adopt in CPU6 is to just hold off firing the interrupt handler when the instruction just completing is a jump or (successful) branch. The interrupt handler will fire as soon as the next non-branch-or-jump instruction completes, likely the delay slot instruction itself. That's correct - MIPS documents say that branch and following delay slot are to be treated together as a single indivisible unit. Here's the CPU6 code in the IRQ pipleine stage that gives the interrupt request the cold-shoulder treatment:
However that's not quite the end of that particular story. Since the delay slot instruction following it is going to be the interrupt trigger point instead of the branch, the CPU6 design passes on the computed branch target address as an extra `delayed_epc' field in the delay slot instruction's configuration information when it gives the old cold-shoulder, and notes the fact by setting the `delay' bit in the delay slot's configuration too. So a fuller rendition of the code shows:
The "epc" field in the branch instruction's configuration information was filled in with the target address when the branch instruction's target became known, back when it was in the Execute stage of the pipeline. When the delay slot instruction completes in one cycle's time and interrupt processing begins as it's lying in the IRQ pipeline stage, the EPC register is filled from the accompanying configuration information's delayed_epc field, containing the branch target address, instead of being filled with the address of the next instruction in memory (which is recorded as the 'pc' field of the configuration information, being the default value of the PC when the instruction was being decoded back in the Decode stage of the pipeline).
When the interrupt handler return-from-exception (`rfe') instruction eventually runs in the handler code, the EPC register is copied to the PC register in the CPU, and execution then just naturally magically resumes at the branch target address next cycle as a result of the standard Fetch part of the processor cycle, and all is good: the branch has executed, the delay slot instruction has executed, the handler has executed and we have resumed processing at the branch target address. What happens if there is a branch in the branch delay slot position? Many MIPS architectures say that that's illegal code and anything can happen, and so the compiler won't produce it. Certainly it's a difficult question to answer as to what will happen in that kind of case. It should be alright under CPU6. Why not try! Of course the top-level interface is unchanged with respect to CPU5 and earlier:
In particular, the command line expects program code and and a handler. Two files, in other words. Not one. In fact, beyond the few extra code inserts described above and in the exercise on CPU3, there is no difference at all with respect to CPU5, neither internally nor externally. An interrupt coprocessorEarly MIPS machines executed interrupt handlers on a second co-processor, in order to relieve the main CPU of the burden. With only one interrupt line, handlers had at least some polling to do in order to determine which peripheral raised the interrupt request, so there was evidently some advantage to be gained, the question being just how much. Processors were considerably slower than today, with on the order of 10MHz instead of 1GHz clocks, so interrupt processing could occupy a proportionately higher amount of the available processor cycles. At any rate, you can measure the advantage gained for yourself, with the CPU7 model. The new model consists of a pair of CPU6 model processors, one with interrupts disabled, and one with interrupts enabled, via their STATUS register. Interrupts are executed only on the CPU with interrupts enabled - for the rest of the time it executes a busy loop in a single branch instruction that jumps to itself at location 0x0 in memory. This design aims for minimal changes between processor and co-processor - indeed, the original MIPS interrupt co-processors came off the same assembly line, and were entirely the same as the main CPU, so the design aim is correct. The Cpu7 main() routine Java code sets up two CPU7 processors, one which it names as `cpu' (the main processor) and one of which it names as `ipu' - the `interrupt processing unit'. One has interrupts blocked, and the other has them enabled: CPU7 cpu = new CPU7(); CPU7 ipu = new CPU7(); // new! ... cpu.STATUS.write(0); // block interrupts on cpu ipu.STATUS.write(1<<3); // enable interrupts on ipu Bit 3 in the STATUS register is the interrupts enable bit. The two CPU7 processors, cpu and ipu, are really exactly the same internally as CPU6 processors and you should think of them as such. The name does not matter. The CPU7 Java class announces that it is an extension of the Java CPU6 class, but the class is marked `final' and contains no extra methods or attributes! So a CPU7 processor model is just exactly the same as a CPU6 processor model. Setting bit 3 of the STATUS register in ipu and not setting it in cpu is not an architectural change to the model. They are the same inside as CPU6 processors. However, they have been made to share access to the same memory and cache. They each have their own PC and IR, and STATUS, CAUSE and EPC registers. They each have their own set of 32 general registers, plus LO and HI registers. They are essentially independent, identical, CPUs. The free-running console unit has to be told to raise interrupts with the `ipu' processor, not the `cpu' processor, via its IO bus, or it won't get a response: // processor ipu, not cpu, handles peripherals' IRQs console.screen.iobus = console.keyboard.iobus = ipu.iobus; That's all the change that is required over the Cpu6 setup code. The `ipu' co-processor is launched in its own thread, just as the keyboard and display are: // start the peripherals running new Thread(console.screen).start(); new Thread(console.keyboard).start(); // start the coprocessor new Thread(ipu).start(); // new! // run the emulation cpu.run(); While the `cpu' processor has its PC register set to the address of a code entry point supplied in an ELF file specified on the command line, the `ipu' process has its PC register set to address 0x0: cpu.PC.write(elf[0].text_entry); ipu.PC.write(0); Address 0x0 is where a little one-instruction program has been loaded into memory, to keep the coprocessor busy between interrupts. The program is just: beq $zero,$zero,-4 and the machine code for this instruction is written directly into memory as a region just 4 bytes long, between addresses 0x0 and 0x4:
Both CPUs can see this region, but only one of them will execute the one-instruction program in it - the interrupt co-processor. The instruction machine code is 00010000 00000000 11111111 11111111, and each octet has been written as an (octal) byte code above. Of course, the top-level interfaces are entirely unchanged:
|






