From jmips
SOFTWARE
REQUIREMENTS SPECIFICATION
Introduction
The aim of this project is to help undergraduate
students of Computer Architecture grasp how
computer hardware works.
The difficulty that students brought up on a diet
of computer software and academic learning face in
understanding the real world is well-known... lack
of a physics or electronics or engineering or
mathematical or science background in general
tends to mean they have little idea of what the
real world means. This project aims to attack that
gap of understanding by presenting a software
model of real processors that hopefully
computer-science students in particular can relate
to more easily. The idea is to force them to look
at the code in order to achieve a goal that must
be expressed via software. Since the code
implements a model of reality, understanding the
code in order to modify it sneaks in an
understanding of the reality it models.
The project sets out in its documentation certain
hinted sub-projects, the aim of which are to make
the hardware model run faster, by improving the
model in particular `real' ways: improving the
processor cache, improving pipeline optimization,
adding a co-processor, etc. Working through these
sub-projects inevitably induces an understanding
of what the reality behind the representation in
software is. The parts of a processor are modeled,
and the parts are put together as in a real
processor. The result runs like a real processor
does. Putting it together in a `better' way makes
it run `better', according to the performance
measures. Students can see that, and try out
different ideas for improvement, and measure the
effect. But even watching the output helps greatly
with understanding what machine code and assembler
means in terms of hardware.
The project contains five pre-constructed
processor models, demonstrating successively more
sophisticated processor designs, all based around
the real-life 32-bit MIPS R3000 RISC processor.
The models run MIPS 32-bit machine code.
Scope of this
document
This specification identifies requirements for
the jMIPS software (i.e., not the documentation).
System Overview
The software models the parts of a processor and
the way a processor is put together from its
parts, both functionally and physically. Models
represent qualitatively, and to an extent
quantitatively, the goodness or otherwise of a
particular processor design. That is, models
support the taking of measures such as timing
information, cache hit rates, bus bandwidth
occupation, etc. The trends exposed by such
measures qualitatively match the results expected
in reality. For example, adding an L1 cache makes
processors faster, as measured by the model.
Five particular pre-constructed models are
provided.
A wrapper takes an ELF-format executable file and
loads it into a processor model for execution.
Standard I/O is modeled at certain memory mapped
addresses. The wrapper is what the student sees at
top level, and the student may think of it as "a
simulator".
Peripherals are also modeled: console and
keyboard models mediate the standard I/O.
Goals and Objectives
The goal of this project is to provide a toolkit
for modeling MIPS processors in Java, and also
provide some p-reconstructed models. The objective
of the software is thus to model kinds of (32-bit
MIPS) processors as they work in real life. The
choice of the programming language is to match the
background of the students, who will have been
taught Java. Object orientation allows processor
components to be modeled as objects.
Document Overview
Sections 1-4 of this this document are an
overview of the descriptions of requirement
determination, system overview and the goals and
objectives of the project. The requirements of the
JMIPS are categorized and defined in Section 7.
Related Documents
REQUIREMENTS
The software offers to the user as options
affecting execution, either via a GUI or the
command line:
- options relating to the level and kind of
measures reported from a run ("verbose",
"debug", "quiet", ...).
- options relating to tuning settings in the
model being run ("memory latency", ...)
- the pre-constructed model to be run ("1",
"2", ...)
The software always requires to be given
- the name of an executable (ELF-format) file
or files containing machine code to be loaded at
the memory locations specified in the files.
The first file given should contain an
entry-point specification defining where the
program is to be started from. Succeeding files
are not required to contain an entry-point. They
may represent read only data, interrupt handlers,
libraries, etc.
The software then
- runs the loaded code from the given entry
address in the chosen model. with the settings
as defined.
The program stack in particular is started at an
address pre-defined in the software and which may
be tuned.
The program produces as output, depending on
settings, either
- program generated output alone (quiet), or
- that plus an execution trace (default), or
- that plus also other information (debug).
Other modes may be added.
- Performance information from the run is
listed at the end of the run, with most
information available in debug mode.
The output will be scrollable, if a scrollable
display device is used, but no very special
provisions are currently made for visualization
beyond the minimum required for reasonable
convenience. The user may always hook the output
(on the standard output and standard error
streams) to an external viewer of their choice!
The user is expected to wait for the end of
output to see if timings have been improved or not
by their latest changes to the model. If more
detail is required, such as running timings, they
may record and inspect the output.
The following activity diagram summarizes the
major ways in which the user is expected to
interact with the software on an immediate
timescale. What is not detailed are the repeated
interactions required to re-program the
pre-programmed models. Those require reading
instructions, editing model code and visualization
of what is being done.
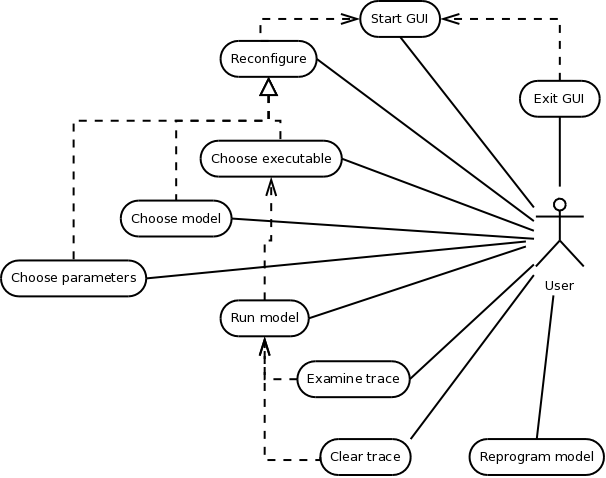
The (close-headed) dependency arrows in general
indicate buttons. For example, the dependency of
Exit on Start is expressed in the software as the
close button on the main window that first starts
up. The dependency comes about because the button
cannot exist until the frame it is on is brought
into existence.
The (open-headed) implementation (dependency)
arrows in general indicate sub-area relationships
within the GUI. For example, the Change Parameters
dependency on Reconfigure is expressed in the
software as a subpanel within the settings area of
the main window.
Alternatively, a dependency may be implemented by
one control inhibiting another. For example, the
dependency of Run on first having selected an
executable to run is expressed in the software by
the Run button being disabled until the executable
is selected (and enabled).
A typical use case is as follows:
Use case #1
| Preconditions |
User is breathing and correctly
positioned in front of console which is
live |
| 1. |
Start GUI |
| 3. |
Choose executable |
| 7. |
Choose model |
| 9. |
Check settings and modify as required |
| 11. |
Run model on executable |
| 13. |
Resize and position trace window and
examine trace |
| 15. |
Clear trace. |
| 17. |
Decide to continue or not. |
| 17.1 |
Go to step 3. |
| 17.2 |
Exit GUI |
| Postconditions |
User has learned from the experience;
switch off console and/or stop breathing,
to taste. |
An elaboration of this use case is to the case
where reprogram the model is carried out
before reexamining the trace.
The software needs to dynamically load recompiled
java classes for that to be feasible, and possibly
may need an "edit" and a "recompile" button.
Optimally, such tasks would be left to the
appropriately specialized 3rd party software.
Expanding the use case to include System
responses yields the following table exemplar:
Use case #1
|
User |
|
System |
| Preconditions |
User is breathing and correctly
positioned in front of console |
|
Console is live |
| 1. |
Start GUI |
2. |
Control window appears |
| 3. |
Select choose executable |
4. |
Search window appears |
| 5. |
Navigate to file and select |
6. |
Search window disappears, file appears
as selected on control window |
| 7. |
Choose model |
8. |
Selected model shown on control window
|
| 9. |
Check settings and modify as required |
10. |
Settings appear checked or unchecked,
as selected |
| 11. |
Run model on executable |
12. |
Run window appears, with trace |
| 13. |
Resize and position trace window and
examine trace |
14. |
Adjust display as scrolled |
| 15. |
Clear trace |
16. |
Run window cleared, and/or disappears
if closed |
| 17. |
Decide to continue or not |
| 17.1 |
Go to step 3 |
| 17.2 |
Exit GUI |
18.2 |
All windows close |
| Postconditions |
User has learned from the experience;
stop breathing, to taste |
|
Console may be shut down |
Other use cases to be added. |