Hindi
From jmips
Java में एक MIPS प्रोसेसरइस jMIPS जावा में आसान उपयोग के लिए खुले स्रोत MIPS प्रोसेसर. आप पहले से ही संग्रह डाउनलोड करनी चाहिए(तिथि करने के लिए प्रतियां पर sourceforge jMIPS project pages)जो भीतर इस दस्तावेज़ की सामग्री के रूप में पाया जा सकता है doc/html उपनिर्देशिका.
सॉफ्टवेयर यहाँ पता बहुत MIPS हार्डवेयर वास्तुकला के बारे में सीखने एड्स और भी कंप्यूटर सिस्टम और आर्किटेक्चर के अधिक सामान्य अवधारणाओं के साथ परिचित बनाता है. वहाँ पाँच प्रोसेसर मॉडल को देखने के लिए और संग्रह में साथ खेलने के लिए कर रहे हैं, 1 के रूप में 5 से यहाँ की पहचान की. संख्या मॉडल में बढ़ती मिलावट के साथ इस प्रकार की वृद्धि,
अगले पन्नों का उपयोग और विस्तार में शायद बुनियादी प्रोसेसर मॉडल के निर्माण की प्रक्रिया के माध्यम से आप ले जाएगा, और फिर पर जाने के लिए अन्य मॉडलों पर विचार करें. मॉडल है कि वे किस तरह बनाया है या उपयोग किया जाता है में अलग नहीं है - यह केवल धर्मशाला कि प्रत्येक मामले में अलग हैं और इसी संदर्भ में एक और की तुलना में तेजी से किया जा रहा है कि एक मॉडल में परिणाम है. आप बारी में प्रत्येक मॉडल प्रोसेसर के साथ काम करते हैं, शायद मॉडल में सुधार लाने के लिए यह तेजी से चलाने के लिए अभी भी मन में उद्देश्य के साथ करना चाहते हो जाएगा. कितनी देर तक यह समग्र और प्रति अनुदेश चलाने लगते हैं डिफ़ॉल्ट मुद्रित उत्पादन के एक है. यदि आप बाहर कैसे लंबे समय तक शिक्षा के प्रत्येक वर्ग के लिए विशेष परिस्थितियों में निष्पादित करने के लिए लेता है जैसे आँकड़े प्राप्त करना चाहते हैं, आप अपने आप को उस के लिए कोड में जोड़ने के लिए होगा. यह खुला स्रोत है! आपको लगता है कि कर सकते हैं. कोड और स्पष्ट रूप से लिखा है और यहाँ पृष्ठों में विस्तार से बताया.
कैसे बुनियादी MIPS प्रोसेसर मॉडल चलाने के लिए.वहाँ एक जावा संग्रह फ़ाइल (एक जार) की आपूर्ति की ज़िप संग्रह या संकुचित टार फ़ाइल में होना चाहिए (उनमें से एक jMIPS परियोजना पृष्ठ पर डाउनलोड लिंक से मिल ). अगर वहाँ नहीं है, तो जाने [[# कैसे बुनियादी एमआइपी सिम्युलेटर संकलन करने के लिए अगले अनुभाग]. संग्रह से (उदाहरण के लिए, संग्रह नाम अपने डाउनलोड विकल्प पर निर्भर करता है) के साथ जार फ़ाइल निकालने चाहिए. % unzip jMIPS-1.7.zip jMIPS-1.7/lib/CPU.jar या % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/CPU.jar इसके अलावा misc directory सामग्री के साथ कुछ निकालने % unzip jMIPS-1.7.zip jMIPS-1.7/misc/hello_mips32 या % tar xzvf jMIPS-1.7.tgz jMIPS-1.7/lib/hello_mips32 तो Cpu1 class किसी भी मंच पर एक Java वर्चुअल मशीन (JVM) द्वारा चलाए जा सकता है. आप Linux के अंतर्गत के साथ कर सकता है % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 उदाहरण के लिए: % java -cp jMIPS-1.7/lib/CPU.jar CPU.Cpu1 -q jMIPS-1.7/misc/hello_mips32 Hello world % यदि आप पैकिंग को खोलने के 1.7d या बाद में संग्रह कर रहे हैं, आप एक साथ पांच पूर्व निर्मित मॉडल लांच GUI मिलेगा. Run % jMIPS-1.7d/lib/CPU.jar % 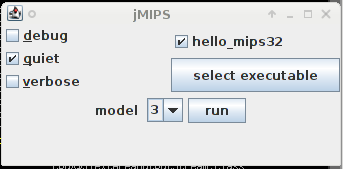 और आप मिल जाएगा सही खिड़की पर दिखाया. यह पहले से
ही misc स्रोत संग्रह के उपनिर्देशिका है, तो है कि
उपलब्ध के रूप में दिखाया गया है और डिफ़ॉल्ट रूप से
चलाने के लिए तैयार से बाहर एक hello_mips32
निष्पादन योग्य फ़ाइल लेने के लिए इस्तेमाल किया गया
है, और "शांत" स्विच पहले भी चयन किया गया है!
सीपीयू मॉडल छवि में "3" में सेट बदलने के लिए,
"मॉडल" नियंत्रण का उपयोग करें. फिर मारा "run" और
एक पॉप अप विंडो रन से युक्त उत्पादन होगा. (यदि आप
वास्तव में रोमांचक UML उपयोगकर्ता इस GUI के साथ
बातचीत के लिए "गतिविधि आरेख" देखना चाहते हैं, बस
इस छोटे आइकन पर क्लिक करें: कैसे बुनियादी MIPS प्रोसेसर मॉडल compile करने के लिए.यदि आप चाहते हैं या जावा स्रोत कोड को संकलित करने के लिए निष्पादन योग्य कोड प्राप्त है, तो आप ऐसा उपकरण है जो आप उपलब्ध है पर निर्भर करता है के रूप में निम्नानुसार, करना होगा. के बाद से वहाँ उपकरण है कि लोगों को अलग ऑपरेटिंग सिस्टम पर उपयोग के लिए उपयोग किया जाता है के विभिन्न सेट कर रहे हैं, निम्न उप - अनुभाग एक ऑपरेटिंग सिस्टम के लिए विशिष्ट हैं. Linux या Unix के अंतर्गत compilingयदि आप एक Mac पर हैं, और HFS या HFS + प्रारूप फ़ाइल प्रणाली का उपयोग करें, सिस्टम गुण में जाओ और चालू करें case sensitivity". आप की आवश्यकता होगी कि के रूप में अन्यथा आप मामले तह टक्कर में एक दूसरे को, जो आप नहीं चाहते के साथ कई फ़ाइल नाम लाने होंगे. zip या संकुचित tar फ़ाइल असंग्रहीत(फाइल को पाने के लिएjMIPS project pageडाउनलोड लिंक)साथ % unzip jMIPS-1.7.zip या % tar xzvf jMIPS-1.7.tgz
तो नव unpacked किया फ़ाइल पदानुक्रम में "src/" निर्देशिका खोजने और इसे करने के लिए अपने वर्तमान निर्देशिका ( परिवर्तन निर्देशिका आदेश cd jMIPS-1.7/src का उपयोग करने के लिए ऐसा करने के लिए). मैं जेनेरिक जावा bytecode उत्पादन के लिए पसंद करते हैं एक जावा वर्चुअल मशीन (झाविमो) के लिए, के साथ % javac CPU/Cpu1.java /src निर्देशिका, और फिर परिणामी Cpu1.class फ़ाइल किसी भी मंच पर एक JVM द्वारा चलाया जा सकता है. आप Linux के अंतर्गत के साथ कर सकता है
% java CPU/Cpu1 -q ../misc/hello_mips32 उदाहरण के लिए: % java CPU/Cpu1 -q ../misc/hello_mips32 Hello world % एक जार फ़ाइल का निर्माण पहली इमारत सभी जावा वर्ग फ़ाइलों का एक सवाल है:
% javac CPU/*.java % और फिर एक जार फ़ाइल के साथ % jar cf ../lib/CPU.jar CPU/*.class % वास्तव में, सिर्फ एक जार सम्पीडन के बिना किए गए पैकेज के एक ज़िप संग्रह है, और एक अतिरिक्त प्रकट फ़ाइल के साथ भी शामिल है. तो तुम यह सिर्फ एक ज़िप archiver का उपयोग और तुम जरूरी जार उपकरण की जरूरत नहीं कर सकते हैं. पर विवरण देखें जावा ट्यूटोरियल साइट या एक मौजूदा जार तुलना के लिए ज़िप archiver का उपयोग कर फ़ाइल की जांच. विंडोज के अंतर्गत संकलनFse2602 एक बार आईडीई के सभी जरूरत की निर्देशिकाओं और नियंत्रण फ़ाइलों का निर्माण करने पर,स्रोत कोड संग्रह से 'src/CPU/ directory *.java' फाइल की प्रतिलिपि बनाएँ, और NetBeans द्वारा बनाई गई jMIPS परियोजना निर्देशिका की एक नई "src / CPU /" उपनिर्देशिका में कॉपी करें. ज़िप संग्रह के अंदर से सीधे एक ऑपरेटिंग सिस्टम प्रतिलिपि आदेश का उपयोग करें, यदि संभव हो तो.अन्यथा, Windows द्वारा कुछ फ़ाइल के नामों के 'फोल्ड' हो सकते है. अगर Netbeans में आयात करने के लिए, या ज़िप से संकलन करने के लिए एक मेनू विकल्प हो,वह सबसे सही होगा. आईडीई आप के स्रोत कोड क्षेत्र के पॉ़पयूलेट करने का पता लगाएगा, और एक CPU " पैकेज " और अपने जावा फ़ाइलें शामिल करने के लिए अपने `Source Packages'ट्री दृश्य(jMIPS/src निर्देशिका )का विस्तार करेगा. यदि आप चाहें, आप व्यवस्थित रीति से प्रत्येक
प्रोसेसर मॉडल के लिए जावा क्लास फाइलें Cpu1.java,
Cpu2.java,आदि के नाम बदलकर, उदाहरण के लिए,
WinCpu1.java, WinCpu2.java, आदि रख सकते हैं. आप को
प्रत्येक फ़ाइल के निहित क्लास का नाम बदलकर, फ़ाइल
के नाम के साथ मेच करना होगा. Fse2602 एक प्रोसेसर मॉडल चलाने पर नोट्सकमांड लाइन विकल्प का अर्थ है के रूप में इस प्रकार है
% java CPU.Cpu1 hello_mips32 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) 3: 0.000000024s: 0x8003008c: addu $30, $29, $0 4: 0.000000030s: 0x80030090: sw $28, 16($29) ... 218: 0.000001567s: 0x8003000c: lui $3, -20480 219: 0.000001573s: 0x80030010: ori $3, $3, 16 220: 0.000001580s: 0x80030014: sb $3, 0($3) % इस दौड़ .००,००,०१,५८० नकली सेकंड में 220 निर्देश निष्पादित(घड़ी दर 1 GHz नकली है).अनुदेश निष्पादन के प्रति लगभग 5 घड़ी टिक के बराबर.
% java CPU.Cpu1 -q hello_mips32 Hello world %
% java CPU.Cpu1 -d hello_mips32 text start at virtual addr 0x80030000 file offset 0x10000 text end at virtual addr 0x800300e0 file offset 0x100e0 text entry at virtual addr 0x80030080 file offset 0x10080 read 224B at offset 65536 from file 'hello_mips32' stack start at virtual addr 0xb0000000 stack end at virtual addr 0xb0100000 0: 0.000000007s: 0x80030080: addiu $29, $29, -32 1: 0.000000012s: 0x80030084: sw $31, 28($29) 2: 0.000000019s: 0x80030088: sw $30, 24($29) ... %
कृपया स्रोत पर दूर संपादित करें आदेश में और कुछ भी आप की तरह, अपने क्रेडिट फ़ाइल में स्रोत कोड के शीर्ष पर सूची में जोड़ें, और अपने कोड में बदल भेजें - या यह अपने आप प्रकाशित कहीं अगर आप चाहते हैं. MIPS मशीन कोड का उत्पादन करने के लिए प्रोसेसर में चलाने के लिए"Hello World" कार्यक्रम, MIPS R3000 मशीन कोड में तैयार निर्मित hello_mips32 के रूप में संग्रह में फ़ाइल misc/ subdirectory में. (C language) स्रोत कोड संग्रह में. Hello_mips32.c फ़ाइल misc/ directory में है, और इसके लिए MIPS कोडांतरक hello_mips32.s है. मशीन कोड दिया मशीन कोड दे स्रोत से मानक के रूप में संकलित किया गया है के माध्यम से,
% gcc -static -o hello_mips32 -Wl,-e,f hello_mips32.c एक असली MIPS मशीन पर,gcc (यानी., "आman gcc") आदेश पता लगाने के लिए वास्तव में क्या कमांड लाइन में दिए गए विकल्पों का मतलब के लिए मैन्युअल पृष्ठ की जाँच करें. गैर MIPS लेकिन यूनिक्स प्लेटफार्मों पर, निम्न MIPS- gcc पार संकलक सुइट का उपयोग कर एक ही परिणाम प्राप्त करने चाहिए(आप आमतौर पर अपने खोल वातावरण में "setup MIPS"कमांड को चलाने के क्रम में अपने निष्पादन खोज पथ सेट करने के लिए पार संकलक घटक भागों लेने के लिए हो सकता है): % mips-gcc -DMIPS -mips1 -mabi=32 -c hello_mips32.c % mips-ld -Ttext 0x80003000 -e f -o hello_mips32 hello_mips32.o एक MIPS प्रोसेसर का सॉफ्टवेयर मॉडल उपयोगी एक वास्तविक MIPS मशीन के लिए खड़ा है जब "Hello World" मशीन कोड चल रहा है.
% java CPU/Cpu1 -q hello_mips32 Hello world हालांकि, अधिक जटिल मशीन कोड बीच में आता है और बाह्य उपकरणों से जुड़े इस मॉडल को हार हो सकती है. स्रोत कोड में आवासनीचे कैसे स्रोत कोड में ध्यान केन्द्रित करना है और मजेदार है पर कुछ सुझाव हैं:
इसे संपादित करें, अपने आप को शीर्ष पर क्रेडिट और इस परियोजना के लिए संशोधन भेजें. आमतौर पर यह कोड के साथ खुद को परिचित करने के लिए एक अच्छा तरीका है. बुरी तरह से लिखा है कि कैसे और / या मुश्किल यह समझते हैं और इसे ठीक करने की कोशिश कर रहा है के बारे में शिकायत करने के लिए स्वतंत्र लग रहा है. आप निम्नलिखित अनुभाग में कोड पर प्रचुर नोट मिल जाएगा. आप हाथ में इन नोटों के साथ कोड को देखने के लिए चाहते हो सकता है. नोट बड़े पैमाने पर सुविधाओं को समझने के मामले में सबसे उपयोगी साबित केवल बारीकियों स्रोत कोड टिप्पणी के माध्यम से समझाया छोड़ने के लिए होगा.
पहले वेब पर देखने के लिए जाँच के लिए निर्देश क्या करना और क्या उनके लिए मशीन कोड प्रारूप है! आप देखते हैं कि वहाँ एक शाखा शिक्षा और नाम से सिर्फ एक कूद और कड़ी अनुदेश के बीच एक क्रॉस किया जाना चाहिए करने के लिए सक्षम होना चाहिए. मान लीजिए bgezal bgez लेकिन यह एक सफल परीक्षण की स्थिति में कोई jal अनुदेश के रूप में एक ही है (स्थानों वापसी पते में निम्नलिखित अनुदेश का पता रजिस्टर के रूप में ज्यादा एक ही है ra). कि सशर्त उपनेमका आह्वान को लागू करने के लिए उपयोगी है. गूगल की जाँच करें! Hello World के लिए एक द्विआधारी संपादक ("bvi" अच्छी तरह से आप के लिए यूनिक्स पर अगर आप एक vi उपयोगकर्ता कर रहे हैं काम करेंगे, ईमैक्स उपयोगकर्ताओं को पहले से ही पता है कि ईमैक्स एक द्विआधारी संपादक मोड जाएगा) के साथ मशीन कोड संपादित करें और -bnez V0 ,foo ,की जगह bgezal V0 foo का मशीन कोड उपयोग करें. टेस्ट संशोधित मशीन कोड को संशोधित सिम्युलेटर है.
कार्यक्रम के लिए एक प्रतिकारी परिवर्तन बनाने के
क्रम में बचाने के लिए और बहाल $ra वापसी पता शाखा
के आसपास रजिस्टर की जरूरत है, लेकिन आप नई शाखा
अनुदेश ही काम देखेंगे. Fse1200 बुनियादी MIPS प्रोसेसर मॉडल कोड पर नोट्स.MIPS शिक्षा का एक बहुत पारदर्शी सिम्युलेटर कोड में नियमितता वास्तुकला परिणाम निर्धारित किया है. सिम्युलेटर कोड भी उत्पादन कोड का उद्देश्य है कि अधिक परिष्कृत किया जा रहा बिना स्पष्ट है के साथ लिखा गया है. 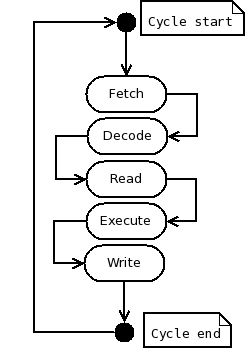 एक परिणाम के रूप में, तुम बाहर कोड का उचित क्षेत्र 'आंख डांट' लगाई द्वारा किसी भी एमआइपी अनुदेश क्या करता है की जाँच कर सकते हैं. CPU1 class कोड वस्तु उन्मुख रैपिंग के न्यूनतम आदेश के माध्यम से चलना आसान बनाने के साथ जरूरी है. यह एक राज्य मशीन है! और इसलिए यह वास्तव में है,. तुम जो कुछ भी देखने की जरूरत है क्रम में लिए CPU1 प्रोसेसर मॉडल को समझने में कि कोड CPU1 class में है, और आप कहीं और देखने की जरूरत है. आप देखेंगे कि वहाँ सिर्फ कोड में एक बड़ा जबकि पाश है. इसे चलाता सामान्य वॉन Neumann लाने - समझाना (पढ़ने डेटा) - निष्पादित (डेटा लिखने) (सही पर साथ आंकड़ा देखें) चक्र के रूप में 1940 के बाद से सभी मुख्यधारा प्रोसेसर डिजाइन में कार्यान्वित किया और सभी कार्रवाई इस लंबे समय से एक के अंदर एम्बेडेड है एक छोटी सन्निहित एमआइपी शिक्षा के प्रत्येक प्रकार करने के लिए समर्पित भाग के साथ पाश. तो आप पाएंगे कि वहाँ के बारे में 10 या 12 में कम सन्निहित पाश के शरीर बनाने के वर्गों रहे हैं. उदाहरण के लिए, कूद निर्देश के साथ काम कर हिस्सा लग रहा है इस तरह ('fetch' के पाश शरीर के शुरू में पहले से ही किया गया है, क्रम में करने के लिए IR रजिस्टर में अगले अनुदेश पढ़ें). यह ज्यादातर ब्लॉक टिप्पणी है:
कि वास्तविक कोड की सिर्फ 6 लाइनों है, गिनती टिप्पणी लाइनों. सारांश में, CPU1 वर्ग द्वारा इनकोडिंग मॉडल के निम्न स्तर के विवरण के बिना एक अमूर्त Von Neumann प्रोसेसर डिजाइन का प्रतीक ठीक कैसे इलेक्ट्रॉनों चारों ओर जा रहा फेरबदल कर रहे हैं और कोड को देख और समझ क्या यह के रूप में करता है में तुम सब पर कोई समस्या नहीं होनी चाहिएहार्डवेयर (टिप: जब आप किसी भी स्रोत कोड के एक छोटे से वर्ग को देखो, मन में एक विशेष प्रश्न के साथ इसे देखो, पता लगाना कैसे समारोह एक्स ताकि आप इसे का अपने आप उपयोग करते हैं, और सब कुछ और उपेक्षा कर सकते हैं प्रयोग किया जाता है जैसे, दोहरानेजब तक) किया. असली हार्डवेयर के लिए सम्मान के साथ अंतर यह है कि इस कोड को एक बार में केवल एक बात कर सकते हैं, जबकि हार्डवेयर में वास्तविक भौतिक विज्ञान परिणाम इन सभी बातों सब यहाँ अनुक्रम में एक प्रोसेसर चक्र के दौरान एक ही समय में किया कर. हालांकि, निष्पादन है समय का उपयोग कर घड़ी वर्ग के तरीकों और क्या हुआ है की अंतिम लेखांकन केवल तब होता है जब एक पूरा प्रोसेसर चक्र पूरा हो गया है. इसलिए क्रम बातें सॉफ्टवेयर में इन बिंदुओं के बीच किया जाता है विशेष रूप से बात नहीं करता, इतने लंबे समय के रूप में आदेश तार्किक समझ में आता है - मॉडल काम करता है. उदाहरण के लिए, ऊपर कूद कोड IR रजिस्टर में दिए गए निर्देशों से पढ़ा डेटा के साथ RA रजिस्टर लिखते हैं. असली हार्डवेयर में, इन दो बातें एक प्रवाहकीय तार भर में प्रसारित एक बिजली के संभावित क्षेत्र का परिणाम के रूप में एक साथ होता है. पढ़ा ऊपर कोड में लिखने से पहले होता है, क्योंकि Java कार्यान्वयन यह है कि रास्ते में की आवश्यकता है! हम Java में नहीं "A पढ़ा और B में परिणाम एक साथ लिख सकते हैं. असली ब्रह्मांड के भौतिक विज्ञान है कि वास्तव में आसान बनाता है! शामिल घटकों द्वारा लेखांकन, लेकिन दोनों पढ़ने और लिखने के लिए एक ही अनुकरण घटना के समय पल रिकॉर्ड और है कि आप अंत में देखेंगे. Class लेआउटस्रोत कोड में निम्नलिखित शीर्ष स्तर वर्गों रहे हैं. केवल पहले पांच या तो नीचे दी गई तालिका में चर्चा के लायक किसी भी कोड होते हैं:
यह एक तथाकथित "डोमेन मॉडल" के डिजाइन है. सॉफ्टवेयर कोड में कक्षाएं हार्डवेयर MIPS प्रोसेसर में वास्तविक भौतिक घटकों के अनुरूप हैं. तरीकों वास्तविक भौतिक कार्रवाई के अनुरूप है कि हार्डवेयर घटकों कर सकते हैं.आभासी संचालन, जैसे कि उन कि सरल आपरेशन के संयोजन के रूप में बना जा सकता है, कोई फर्क नहीं पड़ता कि यह कैसे लग सकता है "सुविधाजनक" सॉफ्टवेयर में लागू नहीं हैं, क्योंकि वे कोई भौतिक अस्तित्व नहीं है . 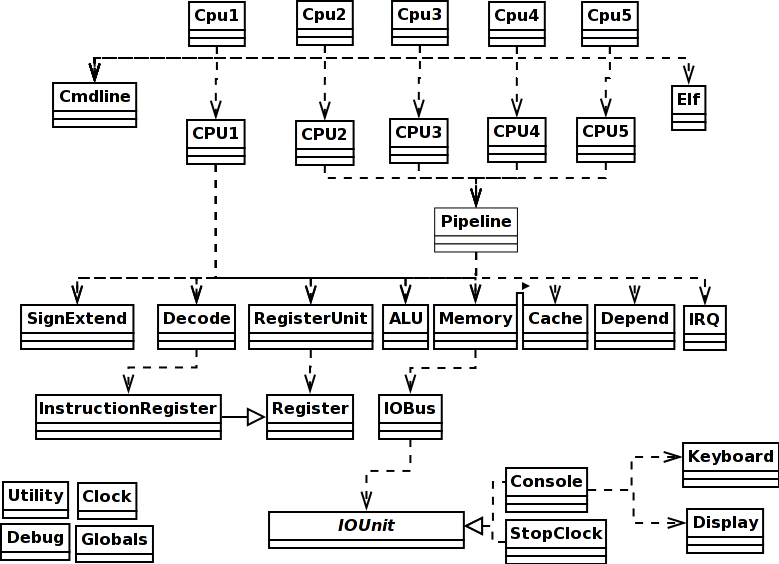
सही पर class आरेख निर्भरता को दर्शाता है. यदि आप Cpu1 सिम्युलेटर के लिए एक एकल कदम सुविधा जोड़ना चाहते हैं, तो आप एक लाने की व्याख्या करना निष्पादित बड़ा लेने की जरूरत है जबकि पाश CPU1 कोड में है और यह उपयोगकर्ता इनपुट के लिए हर नए चक्र के पहले विराम.आप उपयोगकर्ता से एक ("कदम") एक और चक्र को निष्पादित करना चाहिए, एसी ("जारी रखें") यह लगातार साइकिल के लिए वापस भेजना चाहिए, एपी ("प्रिंट") और एक रजिस्टर संख्या या स्मृति पते रजिस्टर या स्मृति दिखाना चाहिएसामग्री, विज्ञापन ("प्रदर्शन") प्रिंट की तरह हो, लेकिन प्रिंटआउट हर कदम पर हो करने के लिए प्रेरित करना चाहिए.
Cpu1 में मुख्य दिनचर्यायह Cpu1 में main दिनचर्या का एक त्वरित और गंदे संक्षिप्त है. आवरण वर्ग जिसका काम यह Java कमांड लाइन तर्क आप इस्तेमाल को समझने की है, और फिर सक्रिय CPU1 प्रोसेसर मॉडल:
आप यहाँ देख सकते हैं कि main कमांड लाइन का उपयोग cmdline डेसिमल विधि का विश्लेषण, निष्पादन योग्य फ़ाइलों कोड जिसका इसे चलाने की एक सूची प्राप्त कर सकते हैं. निष्पादन योग्य फ़ाइलों को क्या `ELF प्रारूप 'के रूप में जाना जाता है में हैं. ELF एक पार मंच प्रयोग में आज कई ऑपरेटिंग सिस्टम में प्रयोग किया जाता मानक और gcc MIPS compilers और assemblers द्वारा उत्पादित प्रारूप है. main दिनचर्या तो आगे चला जाता है और इन एल्फ फ़ाइलों को लोड करता है. यही है,ELF प्रत्येक फ़ाइल नाम है, जो फ़ाइल और प्रविष्टि बिंदु के रूप में इस तरह के अर्क जानकारी की सामग्री, इरादा आभासी पता स्थानों, आदि, जो सभी के परिणामस्वरूप में रखा गया हो डेसिमल पर निर्माताELFobject. तो मुख्य स्मृति और CPU के ढेर क्षेत्र बनाता है, और CPU, स्मृति इकाई और स्मृति इकाई addRegion विधि के एक कॉल के माध्यम से अपने उद्देश्य आभासी पता ढेर के बारे में बताता है. यह कार्यक्रम कोड के विभिन्न हिस्सों यह एल्फ निष्पादन योग्य फ़ाइलों से addRegion अधिक कॉल के माध्यम से उठाया गया है के बारे में स्मृति इकाई बताता है. यह सीपीयू "SP" ("Stack Pointer) को stack के शीर्ष करने के लिए इस बिंदु रजिस्टर सेट रहता है.CPU केPC(`कार्यक्रम 'काउंटर) सेट इरादा कार्यक्रम प्रवेश बिंदु का पता रजिस्टर करने के लिए पहली कमांड लाइन पर नाम फ़ाइल से प्राप्त की और फिर नव निर्मित और CPU "run" में तैयार कॉल विधि. यह सब है. तो पीछा कर रहा है सभी प्रोग्रामर के लिए Cpu1 के बारे में पता करने की जरूरत है:
अगले अनुभाग आप से पता चलता है क्या 'runs it' इसका मतलब है. CPU1 प्रोसेसर मॉडलनिम्नलिखित सभी प्रोग्रामर देख सकते हैं या CPU1 प्रोसेसर वर्ग के बारे में पता करने की जरूरत है. एक (सुंदर कंकाल) निर्माता, और एक विधि है.
run विधि कोड धारणा मुश्किल नहीं है. यह सिर्फ एक बड़ा पाश है:
के रूप में यह टिप्पणी में कहते हैं, पाश चक्र लाने की व्याख्या करना - निष्पादित के आंतरिक भाग होता है. यहाँ यह आता है:
सार fetch/decode/(read)/execute/(write)अनुक्रम कोड में स्पष्ट रूप से दिखाई देता है. एक सशर्त ब्लॉक शिक्षा के प्रत्येक प्रकार (यानी, एक विशिष्ट opcode प्रति) के लिए समर्पित है. टुकड़ा ऊपर ALU संचालन, जो सभी opcode 0 है के इलाज के लिए समर्पित ब्लॉक से पता चलता है. ALU आपरेशन के विभिन्न प्रकार अनुदेश func में क्षेत्र (bigendian लेआउट में शब्द के कम से कम महत्वपूर्ण अंत में पिछले 6 बिट्स) के विभिन्न मूल्यों द्वारा प्रतिष्ठित हैं. IR में शिक्षा के सभी अलग क्षेत्रों से टूट रहे हैं,func सहित समझाना लेबल अनुभाग में,!तो अनुदेश कार्यक्षमता कम जावा कोड लेबल वर्गों में कार्यान्वित किया जाता है READ!, EXECUTE! and WRITE! क्या स्वीकार्य है और क्या स्वीकार्य कोड एक प्रोसेसर मॉडल में नहीं हैध्यान दें कि CPU1 run कोड में कोड शुद्ध अन्तःकरण सेअनुकरणीय सीपीयू हार्डवेयर का उपयोग कर रहा है सब काम करना. पीसी मूल्य Java प्रोग्रामिंग की शक्ति का उपयोग करने के लिए 4 जोड़ने के बजाय ("pc + = 4") उदाहरण के लिए, भाषा FETCH अनुभाग पीसी पीसी रजिस्टर वस्तु read पद्धति का उपयोग करके पढ़ता है, 4 कहते हैं समर्पित का उपयोग fetch योजक execute विधि, और वापस पीसी पीसी रजिस्टर वस्तु write विधि का उपयोग करने के लिए परिणाम मार्गों. यह घना प्रक्रिया है जब "pc += 4" काम किया है हो सकता है! क्या हो रहा है! यहाँ की अनुमति दी है और क्या नहीं है? यह जावा मॉडल में स्वीकार्य है एक हार्डवेयर इकाई द्वारा मूल्य उत्पादन लेबल और अन्य हार्डवेयर इकाइयों को इनपुट के रूप में उन का उपयोग करें. हम 'pc'= के साथ किया है कि '... = 'pc'. यह बात मात्रा की तरह सरल तारों का उपयोग कर एक एक घड़ी चक्र के भीतर CPU circuitry के माध्यम से डेटा संकेत कनेक्ट करने के लिए. यह ठीक है. लेकिन 'पीसी' के रूप में भी एक 4 के रूप में पर्याप्त कुछ भी धोखा दे होगा जावा में है क्योंकि यह समय और circuitry यह वास्तविक जीवन में क्या लगता है. जावा वस्तुओं CPU हार्डवेयर घटकों (alu, register_unit, आदि) के लिए में खड़े उन में एम्बेडेड और जावा कोड में उन का उपयोग सही ढंग से नकली घड़ी अग्रिम बनाता है समय है. वे संगणना के लिए उपयोग करने के लिए ठीक हो. संगणना के लिए वास्तविक जीवन में करने के लिए समय ले. जावा वस्तुओं तरीकों नकली समय अग्रिम. सब ठीक है. "pc += 4" जादुई किसी भी नकली समय लेने के बिना अपेक्षित प्रभाव हासिल होगा की तरह जावा कोड का उपयोग करना तो या तो कर में और कब्जा नहीं नकली हार्डवेयर के किसी भी! यह वास्तविक जीवन की स्थिति की नकल नहीं है, कि जादू की नकल है. नहीं ठीक है. तो किसी भी गणित के लिए Java objects का प्रतिनिधित्व CPU हार्डवेयर, Java गणित नहीं घटकों का उपयोग किया जा सकता है. क्योंकि समझाना खंड में स्पष्ट रूप से इनलाइन जावा कोड है, जो बनाता है यह लगता है जैसे यह सब पर कोई समय लेता है नकली समय में करने में किया जाता है, एक स्पष्ट घड़ी अद्यतन समझाना कोड के अंत में किया गया एम्बेडेड क्रम में सिम्युलेटर रखनेईमानदार समय. उल्टे, अनुभाग लाने कोई अतिरिक्त समय अद्यतन की जरूरत है क्योंकि समय लिया अनुदेश / कैश स्मृति से पढ़ा और घड़ी ठीक से स्मृति कि कोड अनुभाग में यूनिट का उपयोग विधि कॉल के माध्यम से अद्यतन किया जाता है का प्रभुत्व है. इस तरह सिम्युलेटर कोड लिखने में नियम है कि एक जावा कोड चर का उपयोग करने के लिए मूल्यों को पकड़ कर सकते हैं, लेकिन अधिक नहीं (या कम से कम) के लिए क्या धारणा एक नकली घड़ी अंतराल है. वे क्षणभंगुर संकेत मूल्यों की तरह हैं. कोई संकेत मूल्य है कि एक नकली घड़ी अंतराल या अधिक के लिए जारी रहती है रजिस्टर में आयोजित किया जाना चाहिए. यही कारण है कि क्या CPU1run कोड में किया जाता है. कल्पना की दृष्टि से अस्थायी pc और ir मूल्यों और एकाधिक घड़ी अंतराल में सुरक्षित करने के लिए PC IR कराई हैं. Conf objects है कि समझाना outputs के साथ समूहों की तरह यह बनी रहती है लग रहा है, लेकिन के रूप में IR परिवर्तन के रूप में जल्द ही अगले चक्र, conf भी बदल जाएगा. तो यह धारणा अभी IR के कुछ समझाना circuitry के माध्यम से में कांटे की शकल का तार का एक सेट का प्रतिनिधित्व करने और वहाँ कोई अतिरिक्त भंडारण शामिल है. CPU घटक classesइस खंड के शेष जावा वर्गों है कि CPU के भीतर घटकों का प्रतिनिधित्व करते हैं दस्तावेजों. यह एक संदर्भ दस्तावेज है!.तुम सिर्फ एक खंड के रूप में पढ़ सकते हैं और जब आप की जरूरत है, और उससे पहले नहीं. RegisterUnit घटक classesयह घटक छोटे और सुपर CPU के अंदर तेजी से स्मृति शामिल हैं.
स्टर इकाइयों एक सरणी से बना रहे हैंr 32 (वास्तव में एक छोटे से अधिक के क्रम में करने के लिए PC और IR के रूप में अच्छी तरह से शामिल) रजिस्टरों की. read और write विधि कोड में आश्चर्य की बात नहीं है. पढ़ें और / या लिखने के द्वारा या हार्डवेयर रजिस्टर करने के लिए किया जा सकता है. तर्कों की संख्या का कहना है कि कितने रजिस्टर पढ़ा जा रहे हैं और एक ही समय (दो पढ़ता है और एक लिखने का समर्थन कर रहे हैं, एक साथ) में लिखा है. 'बाइट' प्रकार तर्क के रूप में रजिस्टर सूचकांक के लिए बस इतना तुम तर्क है कि तर्क है कि रजिस्टरों के 32 - बिट सामग्री के साथ 5 बिट रजिस्टरों के सूचकांक हैं भ्रमित नहीं है.हाँ, हम 'int' का उपयोग करने के लिए दोनों का प्रतिनिधित्व करते हैं, सकता है, लेकिन तो आप देखते हैं जो विधि प्रकार हस्ताक्षर में देख रहा था, और प्रोग्रामिंग त्रुटियों पर का पालन करेंगे.
किसी भी नोट की ही बात रजिस्टर इकाई का उपयोग करते समय घड़ी का स्वत: अद्यतन है. की गारंटी देता है कि इस घटक का उपयोग कर अनुकरण में ईमानदार समय लेखांकन होता है. Reads और writes एक साथ होता है.जब हम रजिस्टर घटक वर्ग कोड को देखो, हम देखेंगे कि प्रभाव अगले चक्र लेने के लिए लिखते हैं, तो एक अलग कई पढ़ता है और एक लिखने के लिए एक सॉफ्टवेयर में प्रत्येक चक्र रजिस्टर करने के लिए, कर सकते हैं और यह रूप में यद्यपि यह सब एक ही बार में हुआ दिखेगाचक्र के अंत में सिम्युलेटर में.
The ALU classALU घटक CPU भीतर गणित करता है.
ALU class कोड का एक बड़ा टुकड़ा है, लेकिन यह पूरी तरह सरलीकृत है. विधि निष्पादित कोड जो कोड की एक छोटी सी ब्लॉक निष्पादित करने के लिए चुनता है, func (फ़ंक्शन कोड) एक तर्क के रूप में की आपूर्ति मूल्य के आधार पर एक बड़े स्विच बयान के होते हैं. कोड दो इनपुट पूर्णांकों को जोड़ती है a और b परिणाम उपज का उचित तरीका में c और एक ले या शून्य सूचक z:
ऊपर केवल इसके अलावा आपरेशन कोड को दिखाता है, लेकिन यह पूरी तरह से प्रतिनिधि है. ALU कोड का कोई भी किसी भी है कि अधिक से अधिक जटिल है.
मेमोरी घटक classमेमोरी घटक CPU द्वारा देखा के रूप में यादृच्छिक अभिगम स्मृति (RAM) का प्रतिनिधित्व करता है. यहाँ कार्यान्वयन वास्तव में एक साथ दो असली हार्डवेयर घटकों, स्मृति प्रबंधक और स्मृति इकाइयों mashes. यह fussiness 'के लिए दो अलग घटकों के रूप में दो अलग यहां की एक सा हो सकता है, क्योंकि हम एक ही विस्तार में मॉडलिंग की स्मृति के साथ संबंध नहीं है के रूप में हम CPU मॉडलिंग कर रहे हैं, और हम नहीं बल्कि पल के लिए स्मृति के रूप में देखना होगा एक चमकदार, चिकनी, ब्लैक बॉक्स.
एक स्मृति objects के आंतरिक क्षेत्रों की एक सरणी के होते हैं.ये वास्तव में अस्तित्व के रूप में क्षेत्र सीमाओं हमारे स्मृति इकाई की स्मृति प्रबंधक पक्ष में कॉन्फ़िगर. प्रत्येक क्षेत्र स्मृति में पहली बार एक पता है, एक अंतिम पते, और बाइट्स के एक दृश्य स्मृति क्षेत्र सामग्री का प्रतिनिधित्व के होते हैं. वास्तविक जीवन में, एक बार कॉन्फ़िगर (और एक प्रक्रिया के रूप में मक्खी पर विन्यास में परिवर्तन के बाद एक और CPU में प्रवेश करती है), स्मृति प्रबंधक अलग लगाता है विभिन्न क्षेत्रों पर नीतियाँ. केवल पढ़ने के लिए एक क्षेत्र हो सकता है, एक और पढ़ें - लिखें हो सकता है. एक कैश्ड हो सकता है, अन्य नहीं हो सकता है. addRegion विधि स्मृति इकाई में एक और क्षेत्र को कॉन्फ़िगर करने के लिए प्रयोग किया जाता है. Read32be विधि तो बस चक्र है जो देखने के लिए आपूर्ति पता होता है, और रिटर्न आपूर्ति ऑफसेट जब यह सही क्षेत्र पाता है पर क्षेत्र में संग्रहीत डेटा के लिए देख रहे क्षेत्रों में से एक सरणी के माध्यम से. Write32be विधि पूरक है:
स्मृति इकाई भी शामिल हैं विशेष read8 और write8 तरीकों जो पढ़ने और लिखने के केवल एक ही एक समय पर बाइट. जब वे एक सुविधा की तरह लग रहे हो सकता है (और वास्तव में, आंतरिक वे पढ़ सकते हैं और एक समय में 4 बाइट्स लिखने जब वे read32be' और write32be दिग्गजों का उपयोग कर सकते हैं), उनके वास्तविक उपयोग स्मृति के प्रदर्शन में है मैप I/O. आपूर्ति पता सही है, स्मृति इकाई read8 एक और write8' तरीकों का उपयोग पारित एक' के बजाय iobus के लिए स्मृति पर करने का प्रयास. बस और इसे करने के लिए संलग्न के पीछे कई I/O इकाइयों रखना. कोड के नीचे और अधिक विस्तार में वर्णित किया जाएगा, लेकिन सही में अब लेने के लिए सबसे अधिक प्रासंगिक बात यह है कि इस व्यवस्था का मतलब है कि एक विशेष स्मृति पता करने के लिए बात कर अक्षर कुंजीपटल से पढ़ने के लिए और स्क्रीन करने के लिए मुद्रित की अनुमति देता है. यह कहा जाता है I/ O स्मृति प्रतिचित्रित. रास्ता iobus और अवरोध स्मृति इकाई कोड के भीतर लागू कर रहे हैं इस तरह है:
I/O बस पता कंसोल कुंजीपटल इनपुट की, और "1" कंसोल प्रदर्शन उत्पादन की I/O बस पता है "0" है. इन अवरोध के माध्यम से, स्मृति इकाई अनुवाद स्मृति पता GETCHAR_ADDRESS से I/O बस पता 0 जो बस इसे से जुड़े कंसोल से पढ़ता अनुवाद से पढ़ता पढ़ता है. इसी तरह PUTCHAR_ADDRESS के लिए दिलासा देने के लिए लिखता है. स्मृति इकाई read8 कोड और अधिक सही प्रतिनिधित्व के रूप में निम्नानुसार है, हार्ड कोडित की बजाय एक बंदरगाह सूची पर एक पाश के साथ if बयान पता ऊपर पाठ में दिखाया मैच:
हम दूर कंसोल इकाई के लिए एक स्मृति पते पर एक बंदरगाह को जोड़ने के साथ मिल सकता है, लेकिन मैं सामान्य मामले में PUTCHAR_ADDRESS और GETCHAR_ADDRESS ही जरूरी नहीं कर रहे हैं को पूरा करने के लिए पसंद है, इस प्रकार जो तक पहुँच देने के दो अलग अलग बंदरगाह पते दर्जबिल्कुल ठीक उसी तरह में एक ही सांत्वना. यह एक महत्वपूर्ण बेकार नहीं है. यह वास्तविक जीवन में अक्सर होता है कि I/O इकाइयों कई वैकल्पिक पता मैपिंग, जो सभी के उपयोग के लिए इस्तेमाल किया जा सकता है. अतिरेक कभी कभी उपयोगी है, और अक्सर पीछे की ओर - संगतता के कारणों के लिए अनिवार्य है. बंदरगाह सूची करने के लिए इस तरह स्मृति इकाई के भीतर संलग्न है: port.add(new Port(GETCHAR_ADDR, 0)); // translation GETCHAR_ADDR -> bus 0 added port.add(new Port(PUTCHAR_ADDR, 1)); // translation PUTCHAR_ADDR -> bus 1 added
समय: स्मृति के लिए कच्चे उपयोग MEMORY_LATENCY picoseconds ले, 2500 डिफ़ॉल्ट रूप से, यानी, 2.5ns के लिए सेट कर दिया जाता है.आप इस मूल्य में MEMORY_LATENCY वैश्विक स्थैतिक चर वर्ग के साथ नगण्य से बदल सकते हैं. या आप "-oMEMORY_LATENCY = ..." का उपयोग कर सकते हैं कमांड लाइन पर. I/O बस पता मैपिंग के माध्यम से I/O उपकरणों के लिए एक कम समय, नाममात्र CACHE_LATENCY के, जो 1000 picoseconds, यानी 1ns के लिए डिफ़ॉल्ट रूप से सेट कर दिया जाता है लेता है. विचार है कि लिखने पर, ऐसा होता है कि डेटा I/O बस पर शुरू है और फिर CPU चक्र के साथ जारी है. I/O बस अपने दम पर काम करता है (उदाहरण के लिए) प्रिंटर पर डेटा भेजने के लिए, और प्रिंटर अपने आप ही काम करता है डेटा बफर, और बाद में इसे बाहर प्रिंट. पढ़ने पर ऐसा होता है कि कुंजीपटल डिवाइस (उदाहरण के लिए) बफर किसी भी पहले से टाइप अक्षर के लिए बस के माध्यम से पढ़ा है. स्याही कागज पर छिड़काव नहीं है, न keypress 1ns अवधि के भीतर ही मार डाला. लेकिन कैसे CPU स्मृति acceses की भयावहता की देरी के साथ सामना करता है? वे नाममात्र 1GHz की डिफ़ॉल्ट घड़ी दर और कम से कम स्मृति का उपयोग CPU घड़ी चक्र के भीतर पूरी तरह से रखना चाहिए पर पढ़ने के साथ जुड़े 1ns से रह रहे हैं. जवाब यह है कि CPU एक असाधारण लम्बी चक्र के निष्पादित के लिए एक मुख्य स्मृति पढ़ या लिख. लम्बी चक्र निश्चित अवधि की लेकिन इस तरह के एक लंबाई है कि स्मृति यह के भीतर जवाब देने में सक्षम है की है. यह 2.5ns है लंबे समय तक, इसी लगभग स्मृति / 400MB वितरित कर सकते हैं. L1 कैश (जो आप CPU4 डिजाइन में मिलेंगे) के रूप में उपवास के रूप में आधे से भी कम है. आप के लिए प्रतीक्षा करें जब तक आप CPU5 कोड को पूरा करने के लिए इस डिजाइन पर सुधार करने में सक्षम हो जाएगा. IOBus घटक वर्गIOBus CPU, स्मृति और खुद के बीच एक तीन तरह के संचार का हिस्सा है. जब CPU स्मृति में कुछ स्थानों के पते, स्मृति इकाई की स्मृति प्रबंधक बजाय IOBus भाग का उपयोग करने के लिए निर्देशित कर दिये है. IOBus class read8 और write8 तरीकों एक बस ("0", "1", आदि) पते के बजाय एक स्मृति पता ले. के विकल्प को एक स्मृति पता के लिए बस पता अनुप्रेषित. addio विधि है जो बस है, जो इसे एक बस का पता देता है पर एक I/O इकाई (उदाहरण के लिए एक कंसोल वस्तु) रजिस्टर है. बस पते पंजीकरण के क्रम में प्रत्येक इकाई I/O कि एक बारी में करना चाहता है के लिए सम्मानित कर रहे हैं. CPU और स्मृति इकाई के रूप में एक साथ रखा जा रहा है, बस बनाया है और एक एकल कंसोल 0 बस पते के दोनों और 1 पर इस तरह बस के लिए पंजीकृत है: IOBus iobus = new IOBus(); Console console = new Console(); short stdin = iobus.addIO(console); // console registered as bus addr 0 short stdout = iobus.addIO(console); // console registered as bus addr 1 also बस 0 स्मृति इकाई भीतर GETCHAR_ADDRESS के लिए इस्तेमाल मानचित्रण, कंसोल से पढ़ता इसी पते हो जाएगा, और बस 1 PUTCHAR_ADDRESS के लिए मानचित्रण पता हो, इसी कंसोल के लिए लिखता है. I/O बस तरीकों को पूरा इंटरफ़ेस है.
IOUnit एक अमूर्त वर्ग है ("अंतरफलक"). कंसोल वस्तुओं कि इंटरफ़ेस मैच. अंतरफलक की आवश्यकताओं को पूरा एक वस्तु read8 और write8 तरीकों की जरूरत है. इन विधियों को सब पर लेने के लिए नहीं पता है के रूप में वे धारणा सिर्फ अपने स्वयं के इकाई I/O के साथ जुड़े रहे हैं:
एक IOUnit एक पढ़ा अनुरोध पर एक बाइट का उत्पादन, और लिखने के अनुरोध पर एक बाइट अवशोषित. कंसोल में विशेष रूप से वस्तुओं के इन तरीकों है. स्मृति इकाई के निर्माण के कोड के लिए एक सांत्वना कहते हैं, iobus और बंदरगाह सूची के माध्यम से अपने बस एक स्मृति पता करने के लिए पता नक्शे. नतीजा यह है कि सांत्वना वस्तु iobus के माध्यम से स्मृति इकाई से संबोधित स्मृति प्रतिचित्रित पर पहुँचा जा सकता है. हम एक बस शुरू करने के लिए स्मृति इकाई और पल एक एकल इकाई I/O एक एकल कंसोल में है के बीच मध्यस्थता की मुसीबत क्यों चले गए? यह वास्तव में ऐसा है कि हम तथ्य यह है कि बस केवल एक समय में एक I/O इकाई का उपयोग करने के लिए इस्तेमाल किया जा सकता है के द्वारा शुरू की देरी मॉडल कर सकते हैं, और केवल एक समय में एक बाइट नीचे यात्रा कर सकते हैं (एक दिशा में एक समय में)और तथ्य यह है कि वास्तविक जीवन में I/O बस अपेक्षाकृत बहुत धीमा है - 33MHz, के रूप में सीपीयू 1GHz की तुलना में. CPU समय है कि यह 1 बाइट लेता करने के लिए नीचे इस बस I/O यात्रा में 30 निर्देशों पर अमल कर सकते हैं. यदि स्मृति इकाई के लिए बस का उपयोग करने की कोशिश करता है, जबकि यह पहले से ही उपयोग में है, यह परेशानी पैदा करेगा. लगता है कि I/O बस के लिए लिखता है के अलावा कम से कम 30ns या आप पाएंगे यह परेशानी का कारण और अजीब बातें होने की तरह बस त्याग किया जा रहा करने के लिए लिखता शुरू होगा. व्यवहार में, यह एक सौदा ब्रेकर नहीं है. आप मशीन जो भी कोड लिखने के लिए, यह लगभग अनसुना है एक पाश उत्पादन तंग करने के लिए पर्याप्त 30ns भीतर दो I/O बस के लिए लिखता है. CPU1 डिजाइन करने के लिए उस समय में 6 मशीन अनुदेश फांसी देने के लिए संघर्ष. कि रजिस्टरों को बचाने के लिए, एक उपनेमका के लिए एक कूद चलाने, कुछ करते हैं, वापस कूद, रजिस्टर बहाल, एक पाश काउंटर वेतन वृद्धि के लिए पर्याप्त नहीं है, एक बाध्य पाश की जांच आदि वहाँ में कोड है कि अनुकार त्रुटि धारा पर एक शोर करता है अगर I/O बस कभी लादा जाता है और यह व्यवहार में नहीं होता है. यह हालांकि सका. मस्ती के लिए, यह उचित मशीन कोड (MIPS कोडांतरक माध्यम से, बिल्कुल) लेखन के द्वारा होता है, कोशिश करें. आप स्क्रीन पर फटकार शिकायतों की एक धारा मिलेगा. Fse2602fse2602 रियल CPUs की भी अपनी सीमा होती है, और असली प्रोग्रामर उसकी सीमा तक लिखते हैं. तुम लगभग कुछ भी आप कोडांतरक में लिख सकते हो , और नीचे कि धातु का जवाब आप का इरादा जवाब है या नहीं,यह एक सवाल आसानी से अलग नहीं कर सकते हैं. असली प्रोग्रामर 'तो ऐसा नहीं करो ' कहावत का पालन करते हैं. उदाहरण के लिए, यदि आप वास्तविक MIPS कोडांतरक कोड की जाँच करें तो आप पाएंगे कि हर कूद शिक्षा के NOP द्वारा पीछा किया जाता है क्योंकि लगभग हर वास्तविक MIPS मशीन पाइपलाइन और अनुदेश prefetch तंत्र यह अपरिहार्य है कि कूदने के बाद अनुदेश निष्पादित किया जाएगा बनाता है! कंजूस प्रोग्रामर कार्यक्रम पाठ अंतरिक्ष सिद्धांत में सीधे लेबल अनुदेश गैर तुच्छ के साथ एक छलांग के बाद से बचा सकता है, लेकिन वास्तव अगर वे, क्योंकि वे जानते हैं कि क्या होगा नहीं है. विकास के असली प्रोग्रामर (है कि लोगों को अपने अगले पेचेक हो और अपने अगले दोपहर का भोजन खाने के जीवित रहने के) वास्तविकता यह है कि सिद्धांत की तुलना में मजबूत है सिखाया है. Compilers तो या तो नहीं करते, एक ही कारण के लिए. Fse2602 01:50, 23 March 2012 (UTC)fse2602 StopClock घटक वर्ग एक और विशेष I/O पते मानचित्रण अवरोधनएक है प्री सेट. जब HALT_ADDRESS में लिखा जाता है, वह Clock.stop के बुलाने का कारण बनता है जो अनुकरण समाप्त करता है.
एक विशेष अतिरिक्त I/O इकाई है ,stopClock, जो I/O बस पर स्थापित है, इसे अमल में लाने के लिए. यदि आप मेमोरी कोड वास्तव में स्रोत फ़ाइल में किस तरह लग रहा है यह देखे,आप देखेंगे स्मृति इकाई सेटअप कोड में निम्नलिखित की तरह कुछ: StopClock stopClock = new StopClock(); short stpclk = iobus.addIO(stopClock); // stopClock registered as bus addr 3 port.add(new Port(HALT_ADDRESS, stpclk)); // translation HALT_ADDR -> bus 3 added और StopClock write8 विधि केवल एक पतली आवरण दौर है, जो Clock.stop को महत्वपूर्ण कॉल है.
अगर आप स्पेशल इफ़ेक्ट्सका साधन करने के लिए और I/O बनाना चाहते है, stopClock उदाहरण मॉडल के साथ आपको प्रदान करता है:पहले unit को वर्ग के रूप में कोड करें ,write8 read8 मेथोड्स के साथ. CPU वर्ग CPU code में memory build के नया इन्स्तांस बनाए.
StopClock घटक वर्गएक और विशेष I/O पते मानचित्रण अवरोधन पूर्व सेट कर दिया जाता है. यह Clock.stop जब HALT_ADDRESS के लिए लिखा है कहा जा विधि है, जो अनुकरण समाप्त होता है का कारण बनता है!
वहाँ वास्तव में एक विशेष अतिरिक्त I/O कहा इकाई stopClockI/O बस पर यह लागू करने के लिए रखा. अगर तुम बाहर की जाँच मेमोरी कोड क्या वास्तव में स्रोत फ़ाइल में की तरह लग रहा है, आप स्मृति इकाई सेटअप कोड में निम्नलिखित की तरह कुछ ऊपर के बजाय देखेंगे: StopClock stopClock = new StopClock(); short stpclk = iobus.addIO(stopClock); // stopClock registered as bus addr 3 port.add(new Port(HALT_ADDRESS, stpclk)); // translation HALT_ADDR -> bus 3 added And the StopClock write8 method is only a thin wrapper round that vital call to Clock.stop.
=Register वर्ग घटकरजिस्टर याद है कि सीपीयू भीतर घटकों हैं. बाकी सब कुछ प्रत्येक प्रोसेसर चक्र शुरू होता है के रूप में हालांकि यह नए सिरे से हर बार शुरू किया गया. एक रजिस्टर याद मूल्य क्या यह पिछले चक्र था. 32 पता रजिस्टर (और कुछ अधिक) Register unit सीपीयू में घटक.
पंजीकरण वस्तुओं एक आंतरिक पूर्णांक मूल्य की रक्षा. सिद्धांत रूप में पढ़ा है, और बस पूर्णांक का उपयोग तरीकों इस तरह, लिखने:
हालांकि, वहाँ एक मोड़ है. बेहतर असली की कार्रवाई की नकल करने के लिए, दर्ज रजिस्टर, हम व्यवस्था है कि लिखने के परिणाम अगले घड़ी टिक तक नहीं देखा जा सकता है. यही कारण है, रजिस्टर पढ़ने के अंतिम घड़ी टिक के रूप में रजिस्टर में संग्रहीत मूल्य से पता चलता है. आप रजिस्टर लिखने और पढ़ने के रजिस्टर के रूप में आप एक एकल घड़ी टिक की अवधि के दौरान की तरह कर सकते हैं, लेकिन पढ़ने हमेशा वही पुरानी मूल्य दिखाई देगा. उसके बाद आप कॉल Clock.sync तो पढ़ता मूल्य है कि आप पिछले Clock.sync फोन करने से पहले लिखा दिखाना शुरू कर देंगे. को लागू करने के लिए जोड़ दिया है कि हम एक चर xtick घड़ी चक्र जिस पर का वर्तमान मूल्य x लिखा था की संख्या रखती है. वहाँ भी चर xnext है कि एक लिखने फोन द्वारा डाला मूल्य रखती है. बस रिटर्न पढ़ना x अगर वर्तमान घड़ी चक्र अभी भी xtick है, अन्यथा यह xnext में x और अद्यतन xtick लौटने से पहले x चालें.
सुनिश्चित करें किPC के प्रारंभिक सेटिंग्स औरSP xtick main दिनचर्या में CPU पर रजिस्टर शुरू अप प्रभावी रहे हैं. को -1.g प्रारंभिकीकरण है x. तो घड़ी चक्र 0 संख्याPCपर लिखा है, जो xnext सेट. लेकिन में पहली बार पढ़ा पर चक्र का हिस्सा है - निष्पादित लाने - समझाना लाने, 0 चक्र पर भी, xnext में ले जाया जाएगा xऔर पढ़ने के द्वारा लौट आए. यह एक चाल है, लेकिन यह काम करता है. PCसेट औरSP मेंmain 0 प्रोसेसर चक्र में उन मानों उपलब्ध बनाता है. SignExtend घटक वर्गSignExtend घटक CPU है कि एक 32 - बिट संख्या में एक 16 - बिट संख्या में परिवर्तन, इस प्रक्रिया में हस्ताक्षर के संरक्षण के भीतर इकाई है. दूसरे शब्दों में, यह करता है बस 16 शून्य बिट के साथ छोड़ दिया करने के लिए विस्तार नहीं.
ऑब्जेक्ट एक हस्ताक्षर विस्तार और विधि केवल एक 32-bit पूर्ण शब्द के लिए एक 16 - बिट आधे शब्द फैली हुई है, जबकि हस्ताक्षर संरक्षण. सौभाग्य से, जावा में है कि बस (यहाँ निहित) int करने के लिए डाली द्वारा प्राप्त रहा है. तो जावा कोड के रूप में तुच्छ के रूप में हो सकता है!
कंसोल घटक वर्गकंसोल घटक read8' IOUnit इंटरफ़ेस और. Write8 तरीकों के लागू करता है. यह निविष्टियाँ और उत्पादन वर्ण, एक कुंजीपटल से पढ़ने और एक स्क्रीन करने के लिए लिखने कि बात है.
एक कंसोल वस्तु के तरीकों जावा प्रिंट और System.in.read स्क्रीन कुंजीपटल, एक एकल बाइट, चाल तरीकों.
इनपुट पर, अगर कोई चरित्र कुंजीपटल बफर में है, read8 विधि 0 देता है. तेज दिनचर्या में इनकोडिंग समय इस व्यवहार के तत्काल प्रकृति को दर्शाता है. सीपीयू मतदान कुंजीपटल इनपुट बफर है. इसमें एक चरित्र है या वहाँ not.rd. है उत्पादन पर, वहाँ पर विचार करने के लिए एक परिमित स्क्रीन बफर है. सभी CPU स्क्रीन उत्पादन कतार है, जो तत्काल में एक चरित्र जगह. यह सांत्वना है कि धीरे धीरे अपनी कतार में अक्षर स्क्रीन करने के लिए बाहर से गुजारें है. यदि सीपीयू तेजी से कतार के लिए लिखते हैं की तुलना में स्क्रीन करने के लिए सांत्वना कतार खाली है, तो कर सकते हैं क्योंकि जल्दी ही अक्षर CPU को थामने नहीं करता है खो दिया जा रहा शुरू! अक्षर खो रहे हैं कि पिछले हैं कि CPU पहले से ही पूर्ण स्क्रीन उत्पादन पंक्ति पर जगह का प्रयास कर रहे हैं. वे कहीं नहीं जाना. Write8 विधि में काफी जटिल समय अनुकरण कोड में है कि सभी परिणाम है. यह ऊपर पुन: पेश नहीं है. लेकिन सावधान! इस सांत्वना इकाई' अंततः अक्षर खो देंगे अगर आप इसे माध्यम से लिखने का प्रयास भी लंबे समय के लिए भी जल्दी से निकास के लिए अनुमति के बिना एक समय में स्क्रीन. आप उस के लिए एक इलाज नहीं मिल रहा जब तक आप CPU5 कोड को दिखेगा. हम वास्तव में तरह किया गया है और माना कि कंसोल तेजी से आंतरिक रूप से देखने के लिए मैं / हे बस हर चरित्र से यह करने के लिए पारित करने में सक्षम होने के लिए पर्याप्त है. यह है कि क्या यह होगा कतार उत्पादन, या चरित्र ड्रॉप के रूप में एक और सवाल है, लेकिन इसे देख यह होगा. यह मामला है कि मैं / हे बस काफी कंसोल के आंतरिक की तुलना में तेजी से हो सकता है. है वहाँ नहीं जाने! धीरे प्रिंटर एक दर्द का पर्याप्त रूप में है. CPU5 कोड आपको लगता है कि समस्या के साथ सौदा करने की अनुमति देगा.
InstructionRegister घटक वर्गInstructionRegister वर्ग समझाना मिश्रित तर्क में लगा देना. इसके कई तरीके उचित तरह की एक मशीन कोड अनुदेश से क्षेत्र को तोड़ने के लिए, लेकिन वहाँ सभी जटिल या सूक्ष्म जिस तरह से यह किया है के बारे में कुछ भी नहीं है.
तरीकों सभी एक लाइनर हैं.
वहाँ के बारे में 20 अलग व्याख्या करना तरीकों, सब से ऊपर समान हैं. सबसे अच्छी बात करने के लिए स्रोत फ़ाइल स्किम पढ़ा हो और वहाँ क्या कर रहे हैं के बारे में पता है, लेकिन देखो क्या वे केवल जब कहा जाता है या अगर आप एक की जरूरत है. वैश्विक घड़ीसूचना है कि वहाँ केवलइस घटक केएक है. सभी तरीकों (और अपनी आंतरिक विशेषताएँ) स्थैतिक के रूप में चिह्नित कर रहे हैं, जिसका अर्थ है कि वहाँ केवल एक है.
वैश्विक घड़ी एक एकल 64 - बिट संख्या picoseconds की संख्या का प्रतिनिधित्व encapsulates टी स्टार्टअप के बाद से गुजरे. वेतन वृद्धि विधि मूल्य परिवर्तन, पुराने मूल्य लौटने. चल रहा है विधि बूलियन मान देता है सच जब तक रोक बुलाया गया है, जिसके बाद यह झूठी देता है. t वैश्विक आंतरिक पीकोसैकन्ड काउंटर के अलावा, घड़ी जब पिछले पूरे घड़ी चक्र शुरू कर दिया और भावना रखता है जब यह खत्म होता है, जो वस्तुतः किसी भी पीकोसैकन्ड मूल्य पर हो सकता है कारण है. ' रीसेट सेट विधि टी वर्तमान चक्र शुरू और वापस करने के लिए सिंक विधि सेट टी वर्तमान चक्र के अंत / अगले चक्र प्रारंभ बिंदु के लिए. विचार है कि वेतन वृद्धि के लिए कॉल CPU वर्तमान घड़ी चक्र के भीतर सर्किट तत्वों द्वारा शुरू की देरी की घड़ी सलाह. चूंकि तत्वों (ALU, रजिस्टर, आदि) समानांतर में arrayed हैं वेतन वृद्धि देरी कल्पना की दृष्टि से समानांतर में हो. तो वे संचयी नहीं कर रहे हैं इसके बजाय वेतन वृद्धि का प्रभाव समय धक्का है t वर्तमान चक्र के भीतर सभी देरी अभी तक वेतन वृद्धि के माध्यम से की घोषणा की अधिकतम की ओर. आओसिंक की अगली कॉल के मूल्य t अगले घड़ी चक्र प्रारंभ बिंदु के खिलाफ जाँच की जाएगी और अगर t उग आया एक बुरा संदेश अपनी स्क्रीन पर प्रदर्शित किया जाएगा और CPU होगानीचे तोड़ने के लिए और बंद करने के लिए, विचार है कि हम किया गया है CPU घड़ी भी तेजी से CPU घटकों के लिए इसके साथ रखने के लिए सक्षम होने के चल को दर्शाती है . सहायक classesनिम्नलिखित वर्गों के विस्तार कुछ अतिरिक्त वर्ग है जो CPU घटकों का प्रतिनिधित्व नहीं करते. वे वहाँ हैं सिर्फ एक हाथ में मदद देने के लिए Java. उपयोगिता दिनचर्याउपयोगिता वर्ग की अंतिमांश दिनचर्या का एक लपेटना कि आम तौर पर मददगार होते हैं और सभी में हैं और कहीं भी नहीं हैं. वे स्थिर हैं. यही है, वे किसी भी स्थानीय वस्तुओं विशेषताओं के लिए किसी का उपयोग नहीं है. वे सिर्फ शुद्ध कार्यों के हैं.
इन उपयोगिता दिनचर्या प्राथमिक जावा अभ्यास के सामान हैं, और आप उन्हें reimplement अपनी खुद की शैली वरीयताओं को सूट करने के लिए इच्छा हो सकती है.
cmdline दिनचर्याCmdline वर्ग कुछ सामान्य कोड है कि पार्स कमांड लाइन विकल्प और तर्क में मदद करने के लिए प्रयोग किया जाता है लपेटता.
जबकि कमांड लाइन पार्स दिनचर्या वास्तव में काफी जटिल कोड आंतरिक हैं, वे केवल ग्नू getopt पुस्तकालय कॉल के लिए बहुत अच्छी तरह से ज्ञात एपीआई को लागू करने. getopt(3) यूनिक्स man"[ual] आदेश का उपयोग कर देखो. यह एक निजी स्थैतिक विधि यहाँ के रूप में लागू किया है और द्वारा बार - बार कहा जाता है जब तक आदेश पंक्ति समाप्त है विश्लेषण.
काउंटरoptind (तार के सरणी में सूचकांक argv से पारितmain) जोड़ी है हर बार getopt कहा जाता है और opt (के लिए एक शॉर्ट कोडविकल्प पार्स) औरoptarg, (स्ट्रिंग विकल्प तर्क का प्रतिनिधित्व, यदि कोई हो)getopt फोन द्वारा निर्धारित कर रहे हैं. मैं लागू मानक getopt कार्यक्षमता का अधिक से अधिक मैं जरूरत पर बचाया है. विशेष रूप से, मेरी जल्दबाजी में लागू करने के लिए कमांड लाइन पुनःक्रमित कि गैर - विकल्प तर्क पिछले आते परेशान नहीं करता है. परिणाम में, आप कमांड लाइन पर "CPU/Cpu1 hello_mips32-q" लिखने की अनुमति तरह "CPU/Cpu1 -q hello_mips32" कमांड लाइन का उपयोग करना होगा. सभी विकल्पों के लिए सभी गैर विकल्प तर्क से पहले आना होगा. यह खेद के लिए क्षमा चाहते हैं और आप जो वर्तमान में getopt का कार्यान्वयन खराब है कि आलसी निरीक्षण तय करना चाह सकते हैं कुछ है. एल्फ सहायकएल्फ वर्ग है फाइल सिस्टम से एक निष्पादन योग्य फ़ाइल उठा और स्मृति में अपनी मशीन कोड सामग्री को पढ़ने का सब गंदा व्यापार को छिपाने. तुम सच में इसके बारे में पता नहीं करना चाहती.
एल्फ वर्ग कोड जटिल आंतरिक है, लेकिन यह सब होता है एक एल्फ स्वरूपित उठा डेटा के रूप में यह हो जाता है फ़ाइल के माध्यम से अपना रास्ता हैक. जरूरत है सब कुछ और अधिक से अधिक आप एल्फ प्रारूप मानक के बारे में जानना चाहते हैं यूनिक्स में पाया जा सकता है योगिनी (7) man [ual] पृष्ठ और elf.h C हैडर फ़ाइल काम कर रहे एक सी संकलक के साथ किसी भी प्रणाली पर. जावा कोड काफी भारी टिप्पणी की है. एल्फ फाइलेंशीर्षक कई द्वारा पीछा खंड ओं से मिलकर बनता है. अनुभाग के प्रत्येक खंड बना दिया जाता है. एल्फ शीर्षक एक निश्चित प्रारूप प्रारंभिक भाग और एक चर लंबाई ट्रेलर के होते हैं. शीर्ष लेख की निश्चित प्रारूप प्रारंभिक भाग शीर्षक का अनुगामी भाग में पर आगे दो तालिकाओं के आकार और प्रविष्टियों की संख्या और ऑफसेट को परिभाषित करता है. जहाँ तक एक के रूप में देख सकते हैं, शीर्ष लेख अभ्यास तक कुल 64KB में है, तब भी जब यह होता है अपेक्षाकृत कम है. यह संभव हो सकता है कि यह कभी कभी 64KB से रह गया है हो सकता है. कुल हैडर आकार एक निश्चित प्रारूप हैडर के प्रारंभिक भाग में जानकारी के अधिक महत्वपूर्ण बिट है! एल्फ हैडर का अनुगामी भाग में पहली बार तालिका का विश्लेषण का वर्णन और एल्फ फ़ाइल में क्षेत्रों. यह "खंड शीर्ष लेख तालिका" कहा जाता है. जावा कोड खोजों कि तालिका के एक खंड है कि केवल पढ़ने के लिए और निष्पादन के लिए तलाश है. वहाँ केवल एक वास्तविक जीवन में सभी एल्फ फ़ाइलों में इस तरह के खंड प्रतीत होता है, लेकिन शायद वहाँ अधिक हो सकता है. यह खंड है कि एल्फ फ़ाइल के प्रोग्राम कोड हिस्सा शामिल है. इस तथाकथितकार्यक्रम खंड दोनों एककार्यक्रम अनुभाग, और भी केवल पढ़ने के लिए डेटा अनुभाग, और वहाँ आमतौर पर कम से कम बाद के शामिल करना चाहिए. यह प्रकट स्ट्रिंग स्थिरांक एक बात के लिए इस कार्यक्रम के भीतर इस्तेमाल किया, शामिल हूँ. लेकिन कोड कार्यक्रम खंड के भीतर उन दो वर्गों के बीच के अंतर के साथ परेशान नहीं करता है. यह व्यवस्था है कि पूरे कार्यक्रम खंड, जिसमें दोनों कार्यक्रम निर्देशों और केवल पढ़ने के लिए डेटा, एल्फ वस्तु में एक एकल बाइट सरणी के रूप में उठाया जा. ठीक भेद के रूप में हिस्सा है जो यहाँ खो रहे हैं. एल्फ फ़ाइल में खंड शीर्ष लेख तालिका फ़ाइल और प्रोग्राम खंड की लंबाई में ऑफसेट सूचीबद्ध करता है. यह भी आभासी पता है कि यह स्मृति में प्रोग्राम कोड को सफलतापूर्वक चलाने के प्रयोजनों के लिए में लोड किया जाना माना जाता है सूचीबद्ध करता है. यह सब जानकारी है जो एल्फ वस्तु में पार्स द्वारा उठाया है. एल्फ हैडर भी उद्देश्य इस कार्यक्रम के लिए आभासी पता स्थान में प्रवेश बिंदु होते हैं, और वह भी अंतिम एल्फ वस्तु में उठाया जाता है. कोड स्थिरता के लिए जाँच नहीं करता और आप के लिए इस तरह के चेक को जोड़ने (एक प्रवेश बिंदु का पता थे जहां चाहिए कार्यक्रम के लिए लोड किया जाता है स्मृति में क्षेत्र के भीतर की उम्मीद करेंगे!) इच्छा हो सकती है. कोड सानंद एल्फ हैडर, (उप वर्गों के भागों) जो वर्गों को सूची बद्ध करता है में अनिवार्य रूप से दूसरे टेबल पर ध्यान नहीं देता, और इसलिए जो संभावित खंड शीर्ष लेख तालिका से सुक्ष्म अधिक जानकारी देता है. यह "अनुभाग शीर्ष लेख तालिका" कहा जाता है . इस तालिका की उपेक्षा कुछ स्थितियों में घातक हो सकता है. विशेष रूप से, अनुभाग शीर्ष लेख तालिका एल्फ फ़ाइल जहां सभी वर्गों और वर्गों के नाम रखा जाता है के एक क्षेत्र के लिए एक सूचक प्रदान करता है, और है कि संभवतः कार्यक्रम / से खंड खंड का पता लगाने का एक और अधिक विश्वसनीय तरीका है अब जिस तरह से यह किया है. कार्यक्रम अनुभाग का नाम हमेशा ".text". अधिक जानकारी के लिए एल्फ(7) योगिनी पुस्तिका पृष्ठ की जाँच करें. हालांकि, नाम तालिका ही पार्स करने में सरल, एक बार एक यह पाया गया है, और जावा कोड की कोशिश नहीं करता नहीं है! अगर एक यह विशेष रूप से एक में तो पार्स करता है भी एक "bcc." खंड ढूँढने के लिए एक विश्वसनीय तरीका है, अगर वहाँ एक है. अगर यह मौजूद है, कि स्मृति पते जो करने के लिए चुना जाना चाहिए रहे हैं और प्रोग्राम लिखने योग्य खरोंच अंतरिक्ष के रूप में सेवा करने के लिए प्रदान की एक सीमा को परिभाषित करता है. इन bcc वर्गों संकलक उत्पादन में काफी आम हैं. किसी भी चर घोषित सी में स्थिर में हो जाएगा. कोड भी यह देखने के लिए प्रयास नहीं करता, इसलिए यदि एक कार्यक्रमbcc खंड है, सिम्युलेटर जब यह चलता है और विफल कयामत और उदासी भीड़ पर उतरना होगा ... एक हैक है कि छोटे से काम के साथ एक बुलेटिन बोर्ड सर्विस खंड मिल सकता है कि लिखने योग्य और नहीं निष्पादन योग्य के रूप में वर्णित है के लिए लग रही हो सकता है. यह उन दो विशेषताओं के साथ एक और कल्पना करना मुश्किल है. इस अनुभाग के लिए एक खोज जोड़ने और सिम्युलेटर के क्रम में इसी स्मृति क्षेत्र तैयार करें. और जब कोड मानता है कि केवल पढ़ने के लिए एक कार्यक्रम डेटा खंड निष्पादन योग्य कार्यक्रम खंड में पाया जाएगा, वह भी केवल एक अनुमान है जो बाहर बारी के लिए नहीं हो वहाँ बाहर कुछ निष्पादन योग्य फ़ाइलों के सच हो सकता है. कुछ चेक जो एक जोर शोर कर अगर धारणा गलत साबित कर दिया है और वहाँ केवल पढ़ने के वर्गों कहीं जोड़ कृपया. तो वहाँ यहाँ सुधार के लिए कमरे के बहुत सारे है, लेकिन यह चाहे सिम्युलेटर में ही काम करता है या उन निष्पादन योग्य प्रोग्राम फ़ाइलोंचला सकते हैं पर अच्छी तरह से काम करता है के मुद्दे के लिए स्पर्शरेखा है. नायब: संभावित मुद्दों का उल्लेख किया है कई बार आप इस पढ़ा किया गया है द्वारा हल हो सकता है. कोड की जाँच करें! डीबग वर्ग
|




